Stanford CS229: Machine Learning (Autumn 2018)
¶Lecture 1 - Welcome
¶Machine Learning Definition
- Arthur Samuel (1959). Machine Learning:
Field of study that gives computers the ability to learn without being explicitly programmed. - Tom Mitchell (1998) Well-posed Learning Problem:
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measure by P, improves with experience E.
¶Supervised Learning
The most widely used machine learning tool today is supervised learning.
One Example: a database of housing prices
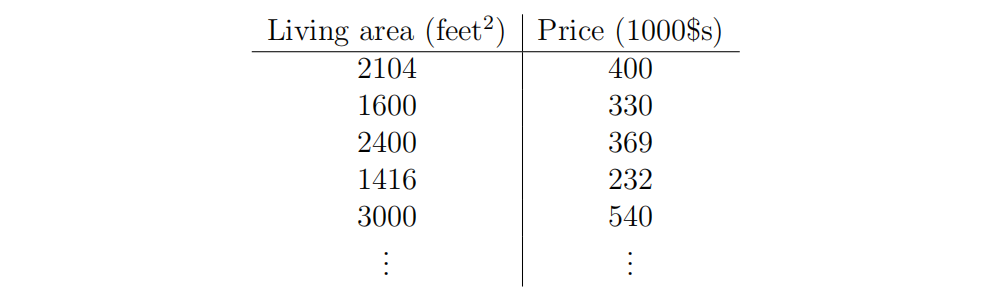
We can plot this data:
Given this dataset, one thing you can do is, um, fit a straight line to it. And then you could estimate or predicts the price to be whatever value you read off on the, um, vertical axis.
So in supervised learning, you are given a dataset with inputs X and labels Y, and you goal is to learn a mapping from X to Y.
Now, fitting a straight line to data is maybe the simplest possible learning algorithm. Given a dataset like this, there are many possible ways to learn a mapping, to learn the function mapping from the input size to estimated price. And so, maybe you wanna fit a quadratic function instead, maybe that actually fits the data a little better.
To define a few more things, this example is a problem called a regression problem. And the term regression refers to that the value y you’re trying to predict is continuous.
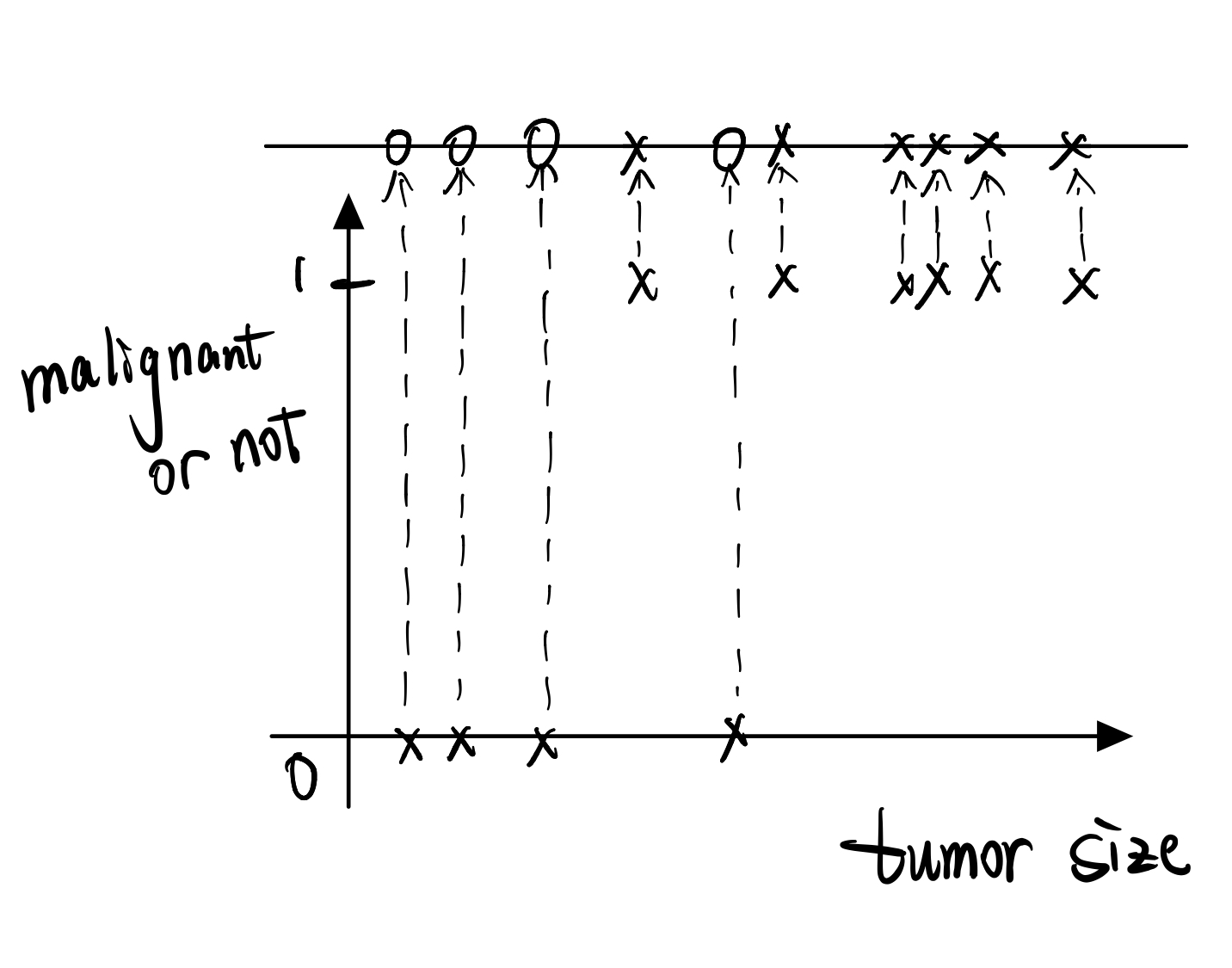
In contrast, here’s a different type of problem. It was a healthcare problem. They were looking at breast cancer or breast tumors, and trying to decide if a tumor is benign or malignant. A tumor is a lump in a woman’s breast and it can be malign or cancerous, or benign meaning roughly it’s not that harmful.

So this is an example of a classification problem and the term classification refers to that Y here takes on a discrete number of variables. For a regression problem, Y is a real number. So we call housing price prediction to be a regression problem, whereas if you have two values of possible output, 0 and 1, call it a classification problem. Um, if you have K discrete outputs, that’s also a classification problem.
Now, I wanna find a different way to visualize this dataset. Let me draw a line on top and map all this data on the horizontal axis upward onto a line. And I use O’s to denote negative examples and I use crosses to denote positive examples.
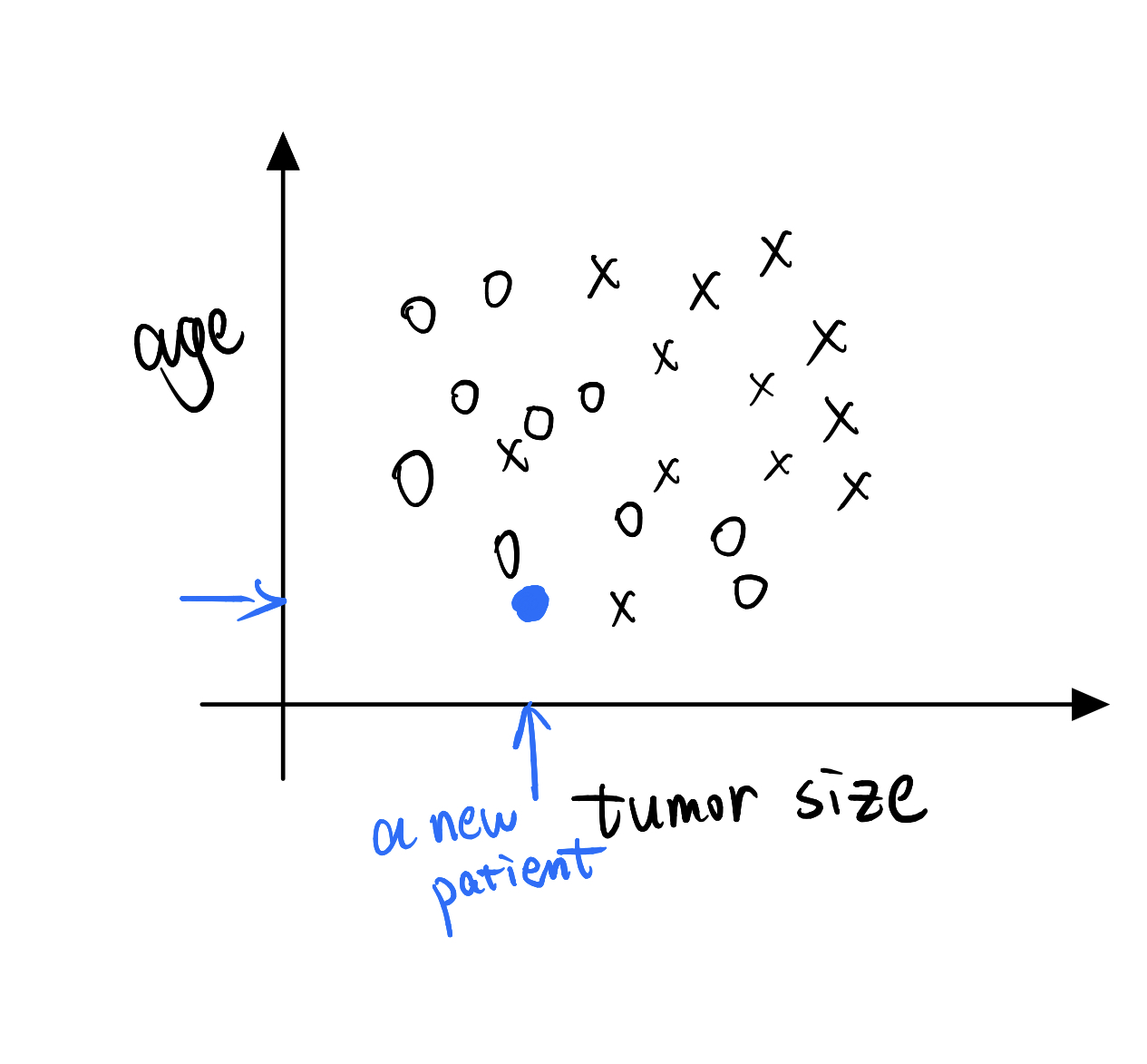
For most of machine learning applications you work with, the input X will be multi-dimensional. You won’t be given just one number and asked to predict another number. Instead, you’ll often be given multiple features and multiple numbers to predict another number. So for example, instead of just using a tumor size to predict- to estimate malignant versus benign tumors, you may have two features where one is tumor size and the second is age of the patient, and be given a dataset that looks like that. where now you task is given two input features, you know, like a two-dimensional vector, to predict whether a given tumor is malignant or benign.
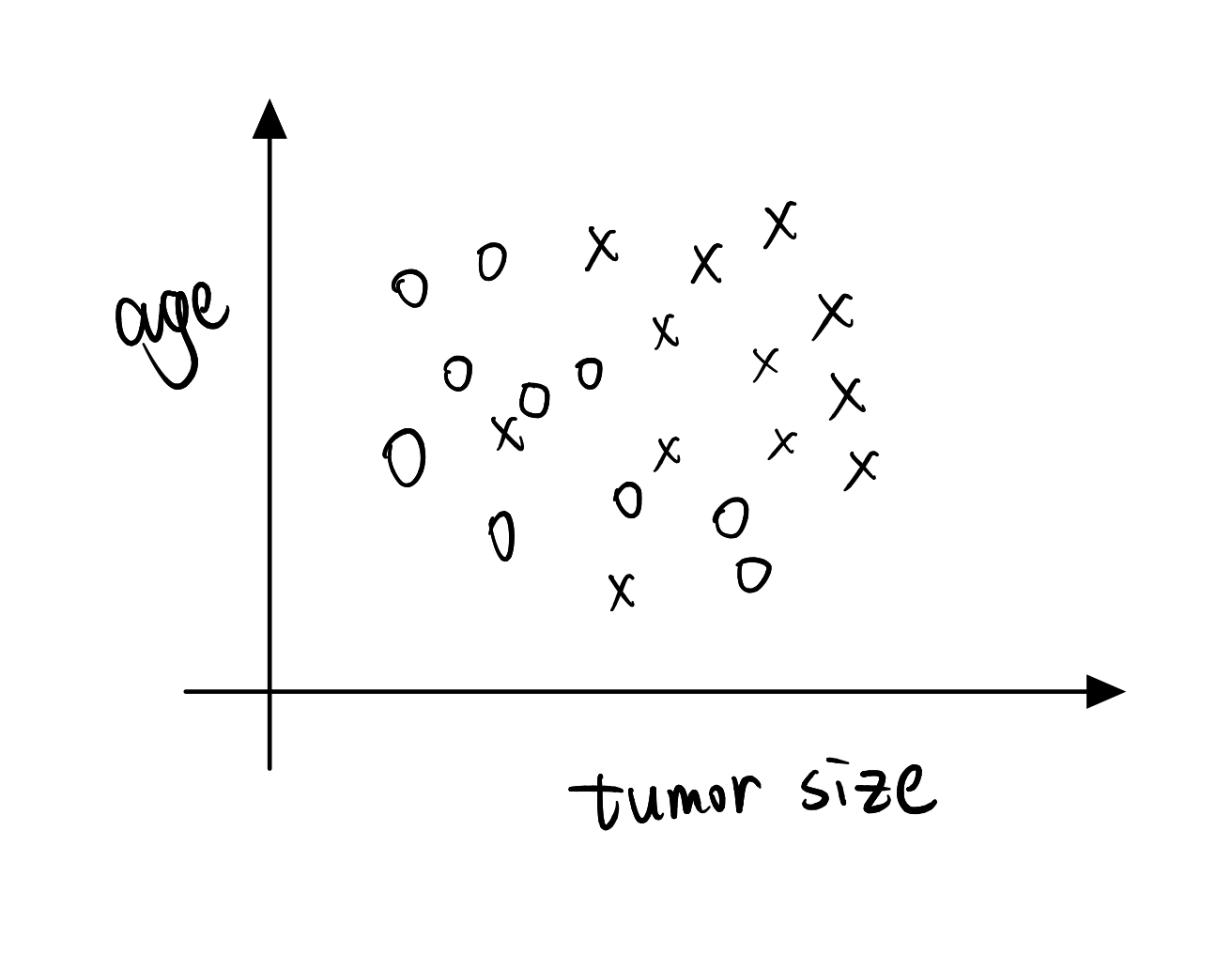
So if a new patient walks in a doctor’s office and that the tumor size is here and the age is here, so that point there, then hope you can conclude that, you know, this patient’s tumor is probably benign, right? Corresponding the O, that negative example.
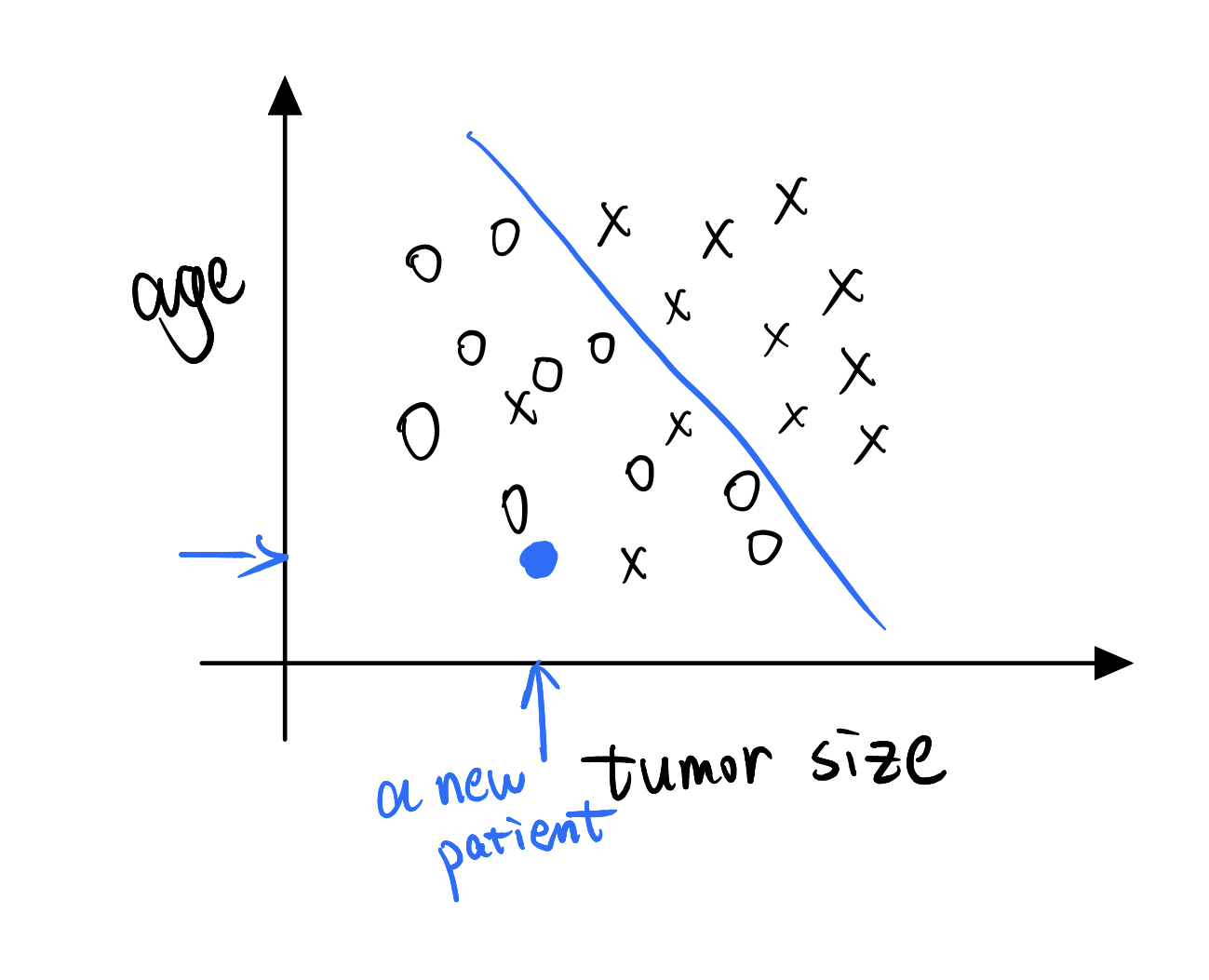
And so, one thing you’ll learn next week is a learning algorithm(the logistic regression algorithm) that can fit a straight line to the data as follows, kinda like that, to separate out the positive and nagative examples.
For an actual breast cancer prediction problem, were using many other features such as clump thickness, uniformity of cell size, uniformity of cell shape, adhesion … A lot more features than just two, which means that you actually can’t plot this data.
you’ll also learn about an algorithm called the Support Vector Machine which uses not one or two or three or 10 or 100 or a million input features, but uses an infinite number of input features(infinite-dimensional vector) to represent a patient.
At the heart of supervised learning is the idea that during training, you are given inputs X together with the labels Y and You give it both at the same time, and the job of you algorithm is to find a mapping so that given a new X, you can map it to the most appropriate output Y.
¶Unsupervised Learning
Unsupervised learning is that giving you a dataset with no labels, which means you’re just given inputs X and no Y, and you’re asked to find me something interesting in this data, figure out interesting structure in this data.
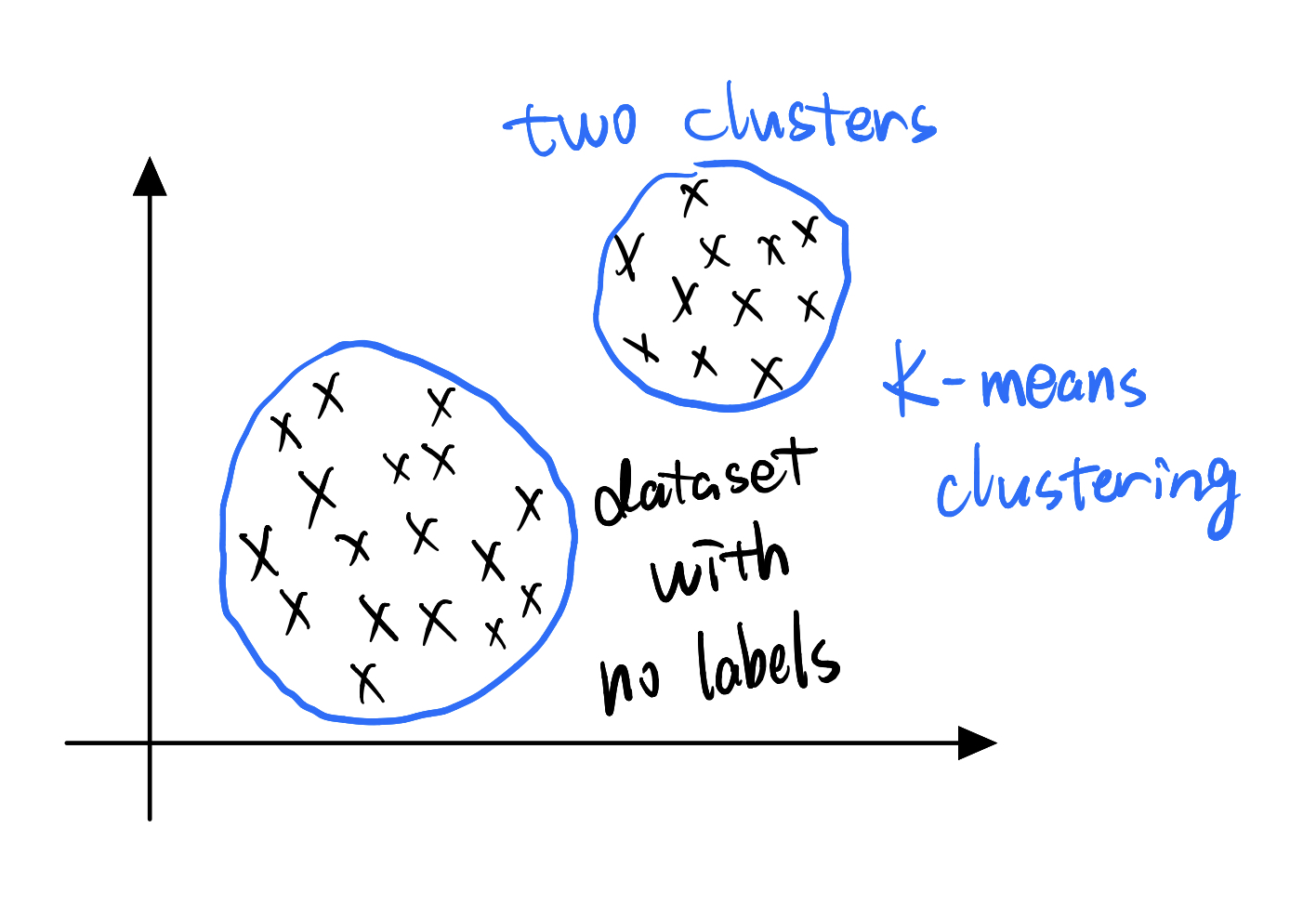
Clustering Algorithm:
Organize computing clusters, figure out what machines workflows are more related to each other and organize computing clusters appropriately
Social network like Linkedln or Facebook or other social networks and figure out which are the groups of friends and which are the cohesive communities within a social network
Market segmentation, look at the customer database and cluster the users together
Astronomical data analysis, group together galaxies
Cocktail party problem:
How can you have an algorithm separate out these voices so you get clean recordings of just one voice at a time. The algorithm you use to do this is called ICA, independent Components Analysis.
¶Something Else
During this lecture, the instructor also mentioned about machine learning strategy, deep learning and reinforcement learning.
An example of reinforcement learning:
I don’t know what’s the optimal way to fly a helicopter. So you let the helicopter do whatever it wants and then whenever it flies well, you know, does some maneuver you want, or flies accurately without jetting around too much, you go, “Oh, good helicopter”. And when it crashes you go, “Bad helicopter” and it’s the job of the reinforcement learning algorithms to figure out how to control it over time so as to get more of the good helicopter things and fewer of the bad helicopter things.
¶Lecture 2 - Linear Regression and Gradient Descent
- Outline
- Linear Regression
- Batch and stochastic gradient descent
- Normal Equation
¶Linear Regression
You remember the ALVINN video, the autonomous driving video that I had shown in class on Monday, um, for the self-driving car video, that was a supervised learning problem. And the term supervised learning meant that you were given Xs which was a picture of what’s in front of the car, and the algorithm had to map that to an output Y which was the steering direction. And that was a regression problem, because the output Y that you want is a continuous value, right? As opposed to a classification problem where Y is the speed.
So I think the simplest, maybe the simplest possible learning algorithm, a supervised learning regression problem, is linear regression. And to motivate that, rather than using a self-driving car example which is quite complicated, we’ll build up a supervised learning algorithm using a simpler example.
Back to our housing prices prediction example, let’s say you want to predict or estimate the prices of houses.
This is data from Portland, Oregon. So you have some dataset like that. And what we’ll end up doing today is fit a straight line to this data.
The process of supervised learning
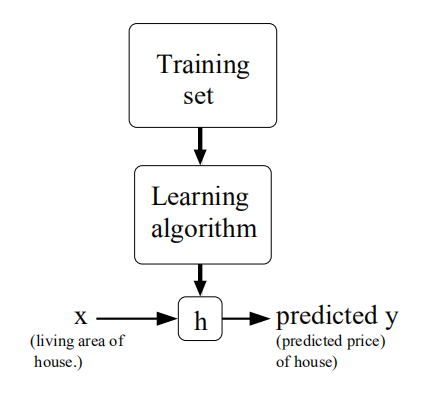
The job of the learning algorithm is to output a function, uh, to make predictions about housing prices. And by convention, I’m gonna call this a function that it outputs a hypothesis. And the job of the hypothesis is, you know, it can input the size of a new house, or the size of a different house that you haven’t seen yet, and will output the estimated price.
So when designing a learning algorithm the first thing we need to ask is, how do you represent the hypothesis, H. And in linear regression, for the purpose of this lecture, we’re going to say that, the hypothesis is going to be that:
$$h(x) = \theta_0 + \theta_1 x.$$The machine learning sometimes just calls this a linear function, but technically it’s an affine function. Doesn’t matter.
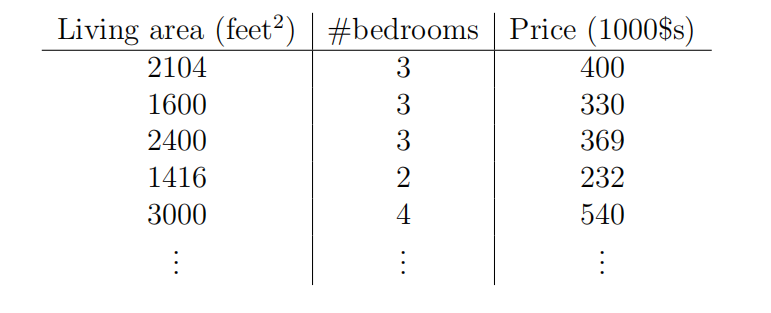
More generally, if you have multiple input features, so if you have more information about these houses, such as number of bedrooms. (“#bedroom” stands for the number of bedrooms.)
In order to make that notation a little bit more compact, we want to write a hypothesis.
$$h(x) = \sum^{2}_{j=0} \theta_j x_j ~~~~~~~~\text{where } x_0 = 1$$And so here theta becomes a three-dimensional parameter:
$$\theta = \begin{bmatrix} \theta_0 \\ \theta_1 \\ \theta_2 \\ \end{bmatrix} $$The features become a three dimensional feature vector:
$$x = \begin{bmatrix} x_0 \\ x_1 \\ x_2 \\ \end{bmatrix} $$To introduce a bit more terminology: $~~~~\theta\text{ : parameters}$
and the job of the learning algorithm is to choose parameters theta, that allows you to make good predictions about your prices of houses.
Back to the problem:
$$\text{choose } \theta \text{ such that } h(x) \text{ is close to } y \text{ for the training examples}$$
Notice: a abbreviation in notation, $h_{\theta}(x) : h(x)$, we use $h_\theta(x)$ to emphasize that the hypothesis depends both on the parameters and on the input features $x$.
So in order to learn a set of parameters what we’ll want to do is choose a parameters $\theta$ so that at least for the houses whose prices you know, that, you know, the learning algorithm outputs prices that are close to what you know where the correct price is for that set of houses.
More formally, in the linear regression algorithm, also called ordinary least squares, we want to
$$\text{choose values of}~~\theta~~\text{that minimizes }\sum^{m}_{i=1}(h_\theta(x^{(i)}) - y^{(i)})^2. $$And so in linear regression, we’re gonna define the cost function:
$$J(\theta) = \dfrac{1}{2}\sum^{m}_{i=1}(h_\theta(x^{(i)}) - y^{(i)})^2.$$so next let’s see how you can implement an algorithm to find the value of Theta that the cost function J of Theta. We’re going to use an algorithm called gradient descent.
¶Gradient Descent
We are going to start with some value of $~\theta~$(say $\theta = \vec{0}$), and we’re going to keep changing $\theta$ to reduce $J(\theta)$
let me show you a visualization of gradient descent, and then we’ll write out the math.
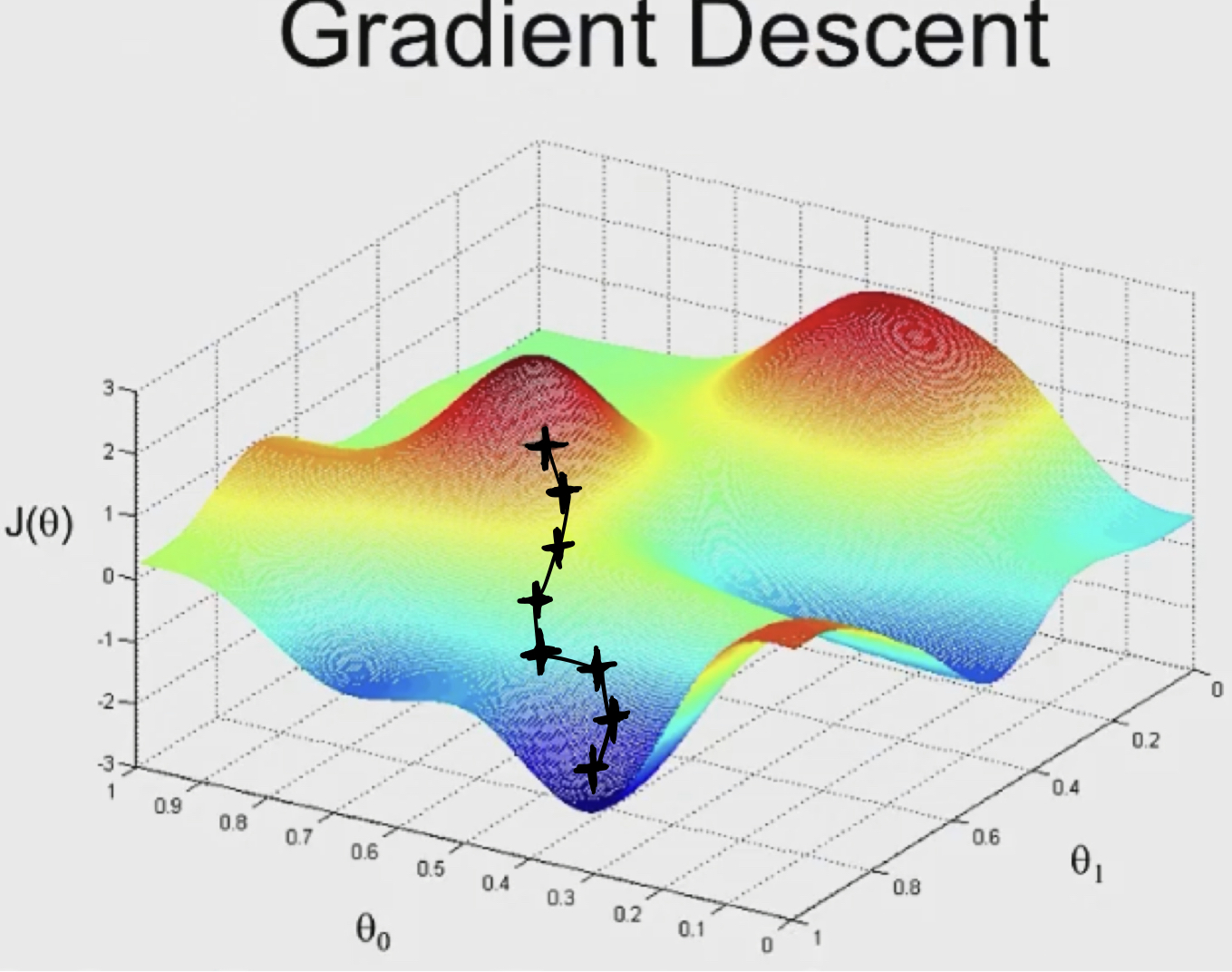
One property of gradient descent is that, depend on where you initialize parameters, you can get to local different points. If you had run gradient descent from a new point, then you would have gotten to a different local optimum, to a different local minima. It turns out that when you run gradient descents on linear regression, there will not be local optimum.
So let’s formalize the gradient descent algorithm.
$$\theta_j := \theta_j - \alpha \dfrac{\partial}{\partial \theta_j}J(\theta)$$The notation “$:=$” denote assignment. And $\alpha$ is called the learning rate.
Q: How do you determine the learning rate?
A: uh, you know, there’s a theory and there’s a practice.
Uh, in practice, you set to 0.01. [LAUGHTER]
In order to implement this algorithm, we have to work out what is the partial derivative term on the right hand side. Lets first work it out for the case of if we have only one training example $(x, y)$, so that we can neglect the sum in the definition of $J$. We have:
$$\begin{array}{lcl} \dfrac{\partial}{\partial \theta_j}J(\theta) & = & \dfrac{\partial}{\partial \theta_j}\dfrac{1}{2}(h_\theta(x) - y)^2 \\ & = & 2\cdot\dfrac{1}{2}(h_\theta(x) - y)\cdot\dfrac{\partial}{\partial \theta_j}(h_\theta(x) - y) \\ & = & (h_\theta(x) - y)\cdot\dfrac{\partial}{\partial \theta_j}\Big(\sum\limits^{n}_{i=0} \theta_i x_i - y \Big) \\ & = & (h_\theta(x) - y) x_j \end{array}$$For a single training example:
$$\theta_j := \theta_j - \alpha (h_\theta(x) - y) x_j$$So I did this with one training example, but, this kind of used definition of $J(\theta)$ defined using just one single training example, you actually have M training examples. Um, the derivative, you know, the derivative of a sum is the sum of the derivatives:
$$\theta_j := \theta_j - \alpha\sum^{m}_{i=1}(h_{\theta}(x^{(i)}) - y^{(i)}) x_j^{(i)}$$So the gradient descent algorithm:
$~~~~~~~~\text{Repeat until convergence }\{\\~~~~~~~~ ~~~~~~~~\theta_j := \theta_j + \alpha\sum\limits^{m}_{i=1}(y^{(i)}-h_{\theta}(x^{(i)})) x_j^{(i)}~~~~~~~~(\text{for every }j)\\~~~~~~~~ \}$
This method looks at every example in the entire training set on every step, and is called batch gradient descent.
Unlike the earlier diagram above which has local optima, it turns out that if $J(\theta)$ is defined the way that, you know, we just defined it for linear regression, is the sum of squared terms, then $J(\theta)$ turns out to be a quadratic function, and so, $J(\theta)$ will always look like a big bowl like this.
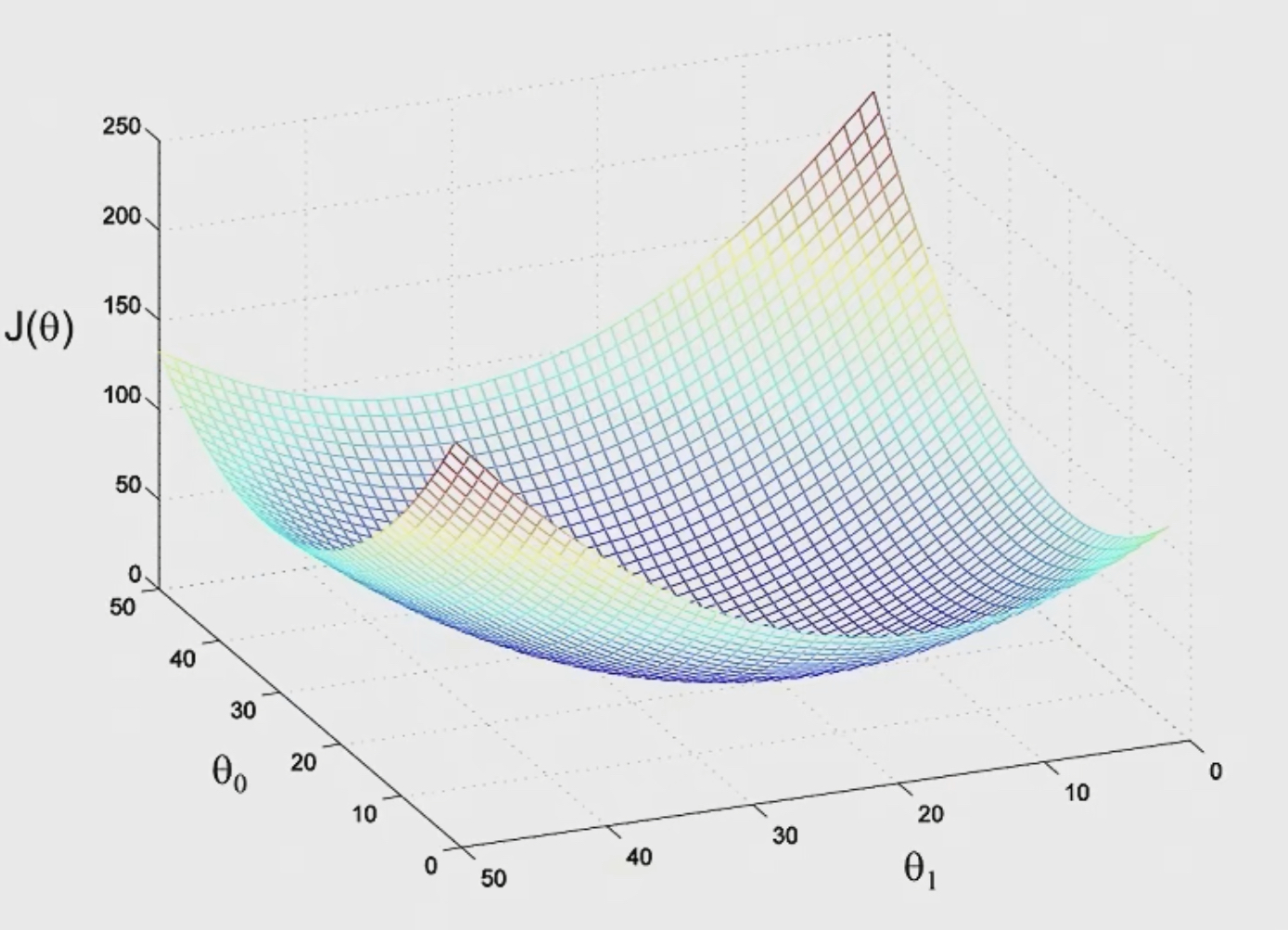
And so $J(\theta)$ does not have local optima, or the only local optima is also the global optimum.
The other way to look at the function is taking horizontal slices and plotting.

As you take steps downhill, because there’s only one global minimum, this algorithm will eventually converge to the global minimum.
And so the question just now about the choice of the learning rate $\alpha$. Um, if you set $\alpha$ to be very very large, then they can overshoot. The steps you take can be too large and you can run past the minimum. If you set to be too small, then you need a lot of iterations and the algorithm will be slow. And so what happens in practice is, uh, usually you try a few values and and and see what value of the learning rate allows you to most efficiently, you know, drive down the value of $J(\theta)$.
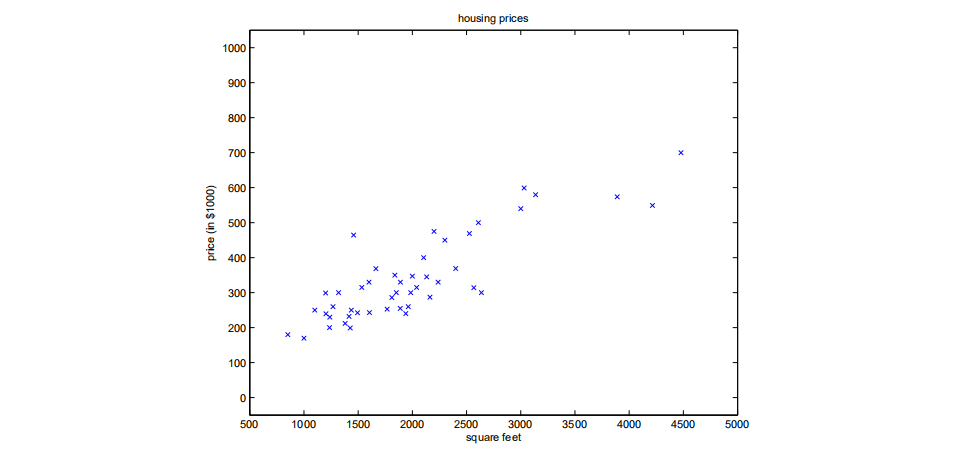
I want to visualize this in one other way, which is with the data. So this is the actual dataset, and there are actually 49 points in this dataset, the number of training examples is 49. When we run batch gradient descent to fit $\theta$ on our previous dataset, to learn to predict housing price as a function of living area, we obtain $\theta_0 = 71.27$, $\theta_1 = 0.1345$. If we plot $h_\theta(x)$ as a function of $x$ (area), along with the training data, we obtain the following figure:
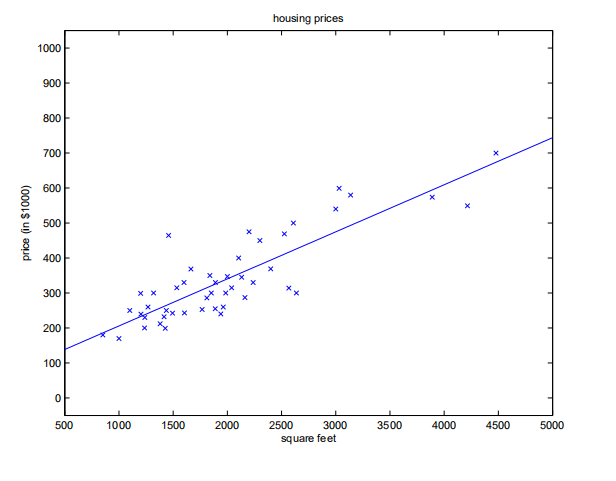
If the number of bedrooms were included as one of the input features as well, we get $\theta_0 = 89.60$, $\theta_1 = 0.1392$, $\theta_2 = 8.738$.
The main disadvantage of batch gradient descent is, every single step of gradient descent requires that you read through your entire data-set, maybe terabytes of data-sets, maybe tens or hundreds of terabytes of data, before you can even update the parameters just once. And if gradient descent needs hundreds of iterations to converge, then you’ll be scanning through your entire data-set hundreds of times. And so this gets expensive. So there’s an alternative to batch gradient descent.
Consider the following algorithm:
$~~~~~~~~ \text{Repeat }\{ \\~~~~~~~~ ~~~~~~~~\text{for i = 1 to m, }\{ \\~~~~~~~~ ~~~~~~~~~~~~~~~~\theta_j := \theta_j + \alpha(y^{(i)}-h_{\theta}(x^{(i)})) x_j^{(i)}~~~~~~~~(\text{for every }j) \\~~~~~~~~ ~~~~~~~~\} \\~~~~~~~~ \}$
In this algorithm, we repeatedly run through the training set, and each time we encounter a training example, we update the parameters according to the gradient of the error with respect to that single training example only. This algorithm is called stochastic gradient descent (also incremental gradient descent).
Whereas batch gradient descent has to scan through the entire training set before taking a single step—a costly operation if $m$ is large—stochastic gradient descent can start making progress right away, and continues to make progress with each example it looks at. Often, stochastic gradient descent gets $\theta$ “close” to the minimum much faster than batch gradient descent. (Note however that it may never “converge” to the minimum, and the parameters $\theta$ will keep oscillating around the minimum of $J(\theta)$; but in practice most of the values near the minimum will be reasonably good approximations to the true minimum.) For these reasons, particularly when the training set is large, stochastic gradient descent is often preferred over batch gradient descent.
¶Normal Equation
Gradient descent gives one way of minimizing $J$. Lets discuss a second way of doing so, this time performing the minimization explicitly and without resorting to an iterative algorithm. In this method, we will minimize $J$ by explicitly taking its derivatives with respect to the $\theta_j$'s, and setting them to zero. To enable us to do this without having to write reams of algebra and pages full of matrices of derivatives, lets introduce some notation for doing calculus with matrices.
¶Matrix derivatives
For a function $f$ : $\mathbb{R}^{m \times n}\longmapsto \mathbb{R}$ mapping from $m$-by-$n$ matrices to the real numbers, we define the derivative of $f$ with respect to $A$ to be:
$$ \nabla_A f(A) = \begin{bmatrix} \dfrac{\partial f}{\partial A_{11}} & \cdots & \dfrac{\partial f}{\partial A_{1n}} \\ \vdots & \ddots & \vdots \\ \dfrac{\partial f}{\partial A_{m1}} & \cdots & \dfrac{\partial f}{\partial A_{mn}} \end{bmatrix} $$Thus, the gradient $\nabla_A f(A)$ is itself an $m$-by-$n$ matrix, whose $(i, j)$-element is $\partial f/\partial A_{ij}$. For example, suppose $A = \begin{bmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{bmatrix}$ is a $2$-by-$2$ matrix, and the function $f$ : $\mathbb{R}^{m \times n}\longmapsto \mathbb{R}$ is given by
$$f(A) = \dfrac{3}{2}A_{11} + 5A^2_{12} + A_{21}A_{22}.$$Here, $A_{ij}$ denotes the $(i, j)$ entry of the matrix $A$. We then have
$$ \nabla_Af(A) = \begin{bmatrix} \frac{3}{2} & 10A_{12} \\ A_{22} & A_{21} \end{bmatrix}. $$We also introduce the trace operator, written “tr.” For an $n$-by-$n$ (square) matrix $A$, the trace of $A$ is defined to be the sum of its diagonal entries:
$$\text{tr }A = \sum_{i=1}^{n} A_{ii}$$If $a$ is a real number (i.e., a $1$-by-$1$ matrix), then $\text{tr } a = a$. (If you haven’t seen this “operator notation” before, you should think of the trace of $A$ as $\text{tr}(A)$, or as application of the “trace” function to the matrix $A$. It’s more commonly written without the parentheses, however.)
The trace operator has the property that for two matrices $A$ and $B$ such that $AB$ is square, we have that $\text{tr}AB = \text{tr}BA$. (Check this yourself!) As corollaries of this, we also have, e.g.,
$$\text{tr}ABC = \text{tr}CAB = \text{tr}BCA,$$
$$\text{tr}ABCD = \text{tr}DABC = \text{tr}CDAB = \text{tr}BCDA.$$
The following properties of the trace operator are also easily verified. Here, $A$ and $B$ are square matrices, and $a$ is a real number:
$$\text{tr}A = \text{tr}A^T$$
$$\text{tr}(A+B) = \text{tr}A + \text{tr}B$$
$$\text{tr}aA = a\text{tr}A$$
We now state without proof some facts of matrix derivatives (we won’t need some of these until later this quarter). Equation $(4)$ applies only to non-singular square matrices $A$, where $|A|$ denotes the determinant of $A$. We have:
$$\nabla_A\text{tr}AB = B^T \tag{1}$$ $$\nabla_{A^T} f(A) = (\nabla_A f(A))^T \tag{2}$$ $$\nabla_A\text{tr}ABA^TC = CAB + C^TAB^T \tag{3}$$ $$\nabla_A|A| = |A|(A^{-1})^T. \tag{4}$$The proofs of these equations are left as an exercise to the reader.
¶Least squares revisited
Armed with the tools of matrix derivatives, let us now proceed to find in closed-form the value of $\theta$ that minimizes $J(\theta)$. We begin by re-writing $J$ in matrix-vectorial notation.
Giving a training set, define the design matrix $X$ to be the $m$-by-$n$ matrix (actually $m$-by-$n$ $+ 1$, if we include the intercept term) that contains the training examples’ input values in its rows:
$$ X = \begin{bmatrix} — ~~(x^{(1)})^T~~ —\\ — ~~(x^{(2)})^T~~ —\\ — ~~(x^{(3)})^T~~ —\\ \vdots \\ — ~~(x^{(m)})^T~~ —\\ \end{bmatrix}. $$Also, let $\vec{y}$ be the $m$-dimensional vector containing all the target values from the training set:
$$ \vec{y} = \begin{bmatrix} &y^{(1)}&\\ &y^{(2)}&\\ &\vdots& \\ &y^{(m)}&\\ \end{bmatrix}. $$Now, since $h_\theta(x^{(i)}) = (x^{(i)})^T \theta$, we can easily verify that
$$\begin{array}{lcl} X\theta - \vec{y} & = & \begin{bmatrix} &(x^{(1)})^T\theta&\\ &\vdots& \\ &(x^{(m)})^T\theta&\\ \end{bmatrix} -\begin{bmatrix} &y^{(1)}&\\ &\vdots& \\ &y^{(m)}&\\ \end{bmatrix} \\ & = & \begin{bmatrix} &h_\theta(x^{(i)}) - y^{(1)}& \\ &\vdots& \\ &h_\theta(x^{(i)}) - y^{(1)}& \end{bmatrix}. \end{array}$$Thus, using the fact that for a vector $z$, we have that $zz^T = \sum_i z_i^2$:
$$\begin{array}{lcl} \dfrac{1}{2}(X\theta - \vec{y})^T(X\theta - \vec{y}) & = & \dfrac{1}{2}\sum\limits^{m}_{i=1}(h_\theta(x^{(i)}) - y^{(i)})^2 \\ & = & J(\theta) \end{array}$$Finally, to minimize $J$, lets find its derivatives with respect to $\theta$. Combining Equations $(2)$ and $(3)$, we find that
$$\nabla_{A^T}\text{tr}ABA^TC = B^TA^TC^T + BA^TC \tag{5}$$Hence,
$$\begin{array}{lcl} \nabla_\theta J(\theta) & = & \nabla_\theta\dfrac{1}{2}(X\theta - \vec{y})^T(X\theta - \vec{y})\\ & = & \dfrac{1}{2}\nabla_\theta(\theta^T X^T - \vec{y}^T)(X\theta - \vec{y})\\ & = & \dfrac{1}{2}\nabla_\theta(\theta^TX^TX\theta - \theta^TX^T\vec{y} - \vec{y}^TX\theta + \vec{y}^T\vec{y})\\ & = & \dfrac{1}{2}\nabla_\theta \text{tr}(\theta^TX^TX\theta - \theta^TX^T\vec{y} - \vec{y}^TX\theta + \vec{y}^T\vec{y})\\ & = & \dfrac{1}{2}\nabla_\theta(\text{tr }\theta^TX^TX\theta - 2\text{tr }\vec{y}^TX\theta)\\ & = & \dfrac{1}{2}(X^TX\theta + X^TX\theta - 2X^T\vec{y})\\ & = & X^TX\theta - X^T\vec{y} \end{array}$$In the fourth step, we used the fact that the trace of a real number is just the real number; the fourth step used the fact that $\text{tr}A = \text{tr}A^T$, and the sixth step used Equation $(5)$ with $A^T = \theta$, $B = B^T = X^T X$, and $C = I$, and Equation $(1)$. To minimize $J$, we set its derivatives to zero, and obtain the normal equations:
$$X^T X \theta = X^T \vec{y}$$Thus, the value of $\theta$ that minimizes $J(\theta)$ is given in closed form by the equation
$$\theta = (X^TX)^{-1}X^T\vec{y}.$$A common question I get is what if X is non-invertible. Uh, that usually means you have redundant features, that your features are linearly dependent, so go and figure out what features are actually repeated leading to this problem.
¶Lecture 3 - Locally Weighted & Logistic Regression
- Outline
- Linear regression (recap)
- Locally weighted regression
- Probabilistic interpretation
- Logistic regression
- Newton’s method
So last Wednesday, you saw the linear regression algorithm, uh, including both gradient descent, how to formulate the problem, then gradient descent, and then the normal equations. What I’d like to do today is, um, talk about locally weighted regression which is a way to modify linear regressions and make it fit very non-linear functions so you aren’t just fitting straight lines. And then I’ll talk about a probabilistic interpretation of linear regression and that will lead us into the first classification algorithm you see in this class called logistic regression, and we’ll talk about an algorithm called Newton’s method for logistic regression.
¶Recap the notation
We use this notation $\big(x^{(i)}, y^{(i)}\big)$ to denote a single training example $(i^{th} \text{example})$ where $x^{(i)} \in \mathbb{R}^{n+1}$ $(x_0 = 1)$, $y^{(i)} \in \mathbb{R}$. And $m$ is the number of training examples and $n$ is the number of features.
$$h_\theta(x) = \sum^{n}_{j = 0}\theta_j x_j = \theta^Tx$$the hypothesis, which is a linear function of the features $x$, including this feature $x_0$ which is always set to $1.$
$$J(\theta) = \dfrac{1}{2}\sum^{m}_{i=1} \Big(h_\theta\big(x^{(i)}\big) - y^{(i)} \Big)^2$$$J$ was the cost function you would minimize, you minimize this to find the parameters $\theta$ for your straight line fit to the data.
¶Locally weighted linear regression
What I want to share with you today is a different way(not feature selection algorithms) of addressing this problem of whether the data isn’t just fit well by a straight line and in particular I wanna share with you an idea called, locally weighted regression or locally weighted linear regression.
Consider the problem of predicting $y$ from $x \in \mathbb{R}$ (or say $x \in \mathbb{R}^2$ and $x_0 = 1$). The leftmost figure below shows the result of fitting a $y = \theta_0 + \theta_1 x$ to a dataset. We see that the data doesn’t really lie on straight line, and so the fit is not very good.
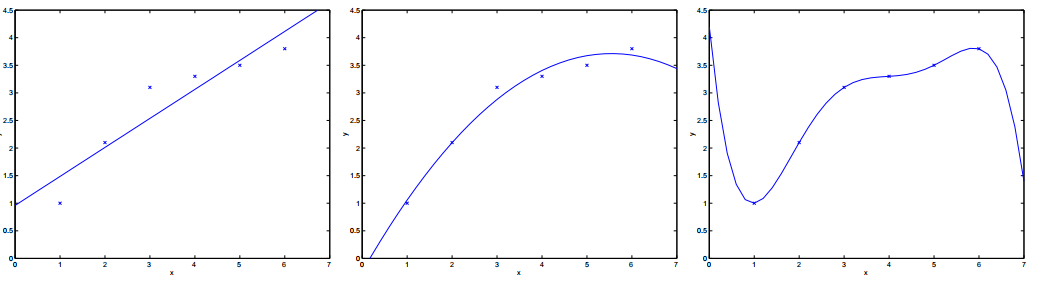
Instead, if we had added an extra feature $x^2$, and fit $y = \theta_0 + \theta_1x + \theta_2x^2$, then we obtain a slightly better fit to the data. (See middle figure) Naively, it might seem that the more features we add, the better. However, there is also a danger in adding too many features: The rightmost figure is the result of fitting a 5-th order polynomial $y = \sum^{5}_{j=0} \theta_jx^j$. We see that even though the fitted curve passes through the data perfectly, we would not expect this to be a very good predictor of, say, housing prices $(y)$ for different living areas $(x)$. Without formally defining what these terms mean, we’ll say the figure on the left shows an instance of underfitting—in which the data clearly shows structure not captured by the model—and the figure on the right is an example of overfitting. (Later in this class, when we talk about learning theory we’ll formalize some of these notions, and also define more carefully just what it means for a hypothesis to be good or bad.)
As discussed previously, and as shown in the example above, the choice of features is important to ensuring good performance of a learning algorithm. (When we talk about model selection, we’ll also see algorithms for automatically choosing a good set of features.) In this section, let us talk briefly talk about the locally weighted linear regression (LWR) algorithm which, assuming there is sufficient training data, makes the choice of features less critical. This treatment will be brief, since you’ll get a chance to explore some of the properties of the LWR algorithm yourself in the homework.
To evaluate $h$ at certain $x$ :
LR algorithm: $~~~~ \text{Fit} ~\theta~ \text{to minimize} ~~\dfrac{1}{2} \sum\limits^{}_{i} \big( y^{(i)} - \theta^T x^{(i)} \big)^2~~ \text{Return} ~~ \theta^T x$
LWR algorithm: $~~~~ \text{Fit} ~\theta~ \text{to minimize} ~~\sum\limits^{m}_{i=1}w^{(i)} \big(y^{(i)} - \theta^T x^{(i)} \big)^2~~\text{Return} ~~ \theta^T x$
Here, the $w^{(i)}$'s are non-negative valued weights. Intuitively, if $w^{(i)}$ is large for a particular value of $i$, then in picking $\theta$, we’ll try hard to make $\big(y^{(i)} - \theta^T x^{(i)}\big)^2$ small. If $w^{(i)}$ is small, then the $\big(y^{(i)} - \theta^T x^{(i)}\big)^2$ error term will be pretty much ignored in the fit.
A fairly standard choice for the weights is
$$w^{(i)} = \exp \Big( -\dfrac{(x^{(i)} - x)^2}{2 \tau^2} \Big)$$If $x$ is vector-valued, this is generalized to be
$$w^{(i)} = \exp\Big(-\dfrac{(x^{(i)}-x)^T(x^{(i)}-x)}{2\tau^2}\Big),$$or
$$w^{(i)} = \exp\Big(-\dfrac{(x^{(i)}-x)^T\Sigma^{-1}(x^{(i)}-x)}{2}\Big),$$for an appropriate choice of $\tau$ or $\Sigma$.
Note that the weights depend on the particular point $x$ at which we’re trying to evaluate $x$. Moreover, if $|x^{(i)} - x|$ is small, then $w^{(i)}$ is close to $1$; and if $|x^{(i)} - x|$ is large, then $w^{(i)}$ is small. Hence, $\theta$ is chosen giving a much higher “weight” to the (errors on) training examples close to the query point $x$. (Note also that while the formula for the weights takes a form that is cosmetically similar to the density of a Gaussian distribution, the $w^{(i)}$'s do not directly have anything to do with Gaussians, and in particular the $w^{(i)}$ are not random variables, normally distributed or otherwise.) The parameter $\tau$ controls how quickly the weight of a training example falls off with distance of its $x^{(i)}$ from the query point $x$; $\tau$ is called the bandwidth parameter, and is also something that you’ll get to experiment with in your homework.
Locally weighted linear regression is the first example we’re seeing of a non-parametric algorithm. The (unweighted) linear regression algorithm that we saw earlier is known as a parametric learning algorithm, because it has a fixed, finite number of parameters (the $\theta_i$'s), which are fit to the data. Once we’ve fit the $\theta_i$'s and stored them away, we no longer need to keep the training data around to make future predictions. In contrast, to make predictions using locally weighted linear regression, we need to keep the entire training set around. The term “non-parametric” (roughly) refers to the fact that the amount of stuff we need to keep in order to represent the hypothesis $h$ grows linearly with the size of the training set.
So I tend to use locally weighted linear regression when I have a relatively low dimensional data set, when the number of features is not too big. So when $n$ is quite small like $2$ or $3$ or something and we have a lot of data. And you don’t wanna think about what features to use, right. So that’s the scenario. So if you actually have a data set that looks like these up in drawing, you know, locally weighted linear regression is a pretty good algorithm.
¶Probabilistic interpretation
When faced with a regression problem, why might linear regression, and specifically why might the least-squares cost function $J$, be a reasonable choice? In this section, we will give a set of probabilistic assumptions, under which least-squares regression is derived as a very natural algorithm.
Let us assume that the target variables and the inputs are related via the equation
$$y^{(i)} = \theta^T x^{(i)} + \epsilon^{(i)},$$where $\epsilon^{(i)}$ is an error term that captures either unmodeled effects (such as if there are some features very pertinent to predicting housing price, but that we’d left out of the regression), or random noise. Let us further assume that the $\epsilon^{(i)}$ are distributed IID (independently and identically distributed) according to a Gaussian distribution (also called a Normal distribution) with mean zero and some variance $\sigma^2$. We can write this assumption as $“\epsilon^{(i)} \sim \mathcal{N}(0, \sigma^2).”$ I.e., the density of $\epsilon^{(i)}$ is given by
$$p(\epsilon^{(i)}) = \dfrac{1}{\sqrt{2\pi} \sigma} \exp\Big( -\dfrac{(\epsilon^{(i)})^2}{2 \sigma^2} \Big)$$This implies that
$$p(y^{(i)}|x^{(i)}; \theta) = \dfrac{1}{\sqrt{2\pi}\sigma} \exp \Big( -\dfrac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2} \Big)$$The notation $“p(y^{(i)}|x^{(i)}; \theta)”$ indicates that this is the distribution of $y^{(i)}$ given $x^{(i)}$ and parameterized by $\theta$. Note that we should not condition on $\theta(“p(y^{(i)}|x^{(i)}, \theta)”)$, since $\theta$ is not a random variable. We can also write the distribution of $y^{(i)}$ as $y^{(i)} | x^{(i)}$; $\theta ∼ \mathcal{N} (\theta^T x^{(i)}, \sigma^2)$.
Given $X$ ( the design matrix, which contains all the $x^{(i)}$'s ) and $\theta$, what is the distribution of the $y^{(i)}$'s? The probability of the data is given by $p(\vec{y}|X; \theta)$. This quantity is typically viewed a function of $\vec{y}$ (and perhaps $X$), for a fixed value of $\theta$. When we wish to explicitly view this as a function of $\theta$, we will instead call it the likelihood function:
$$\mathscr{L}(\theta) = \mathscr{L}(\theta; X, \vec{y}) = p(\vec{y}|X; \theta).$$Note that by the independence assumption on the $\epsilon^{(i)}$'s (and hence also the $y^{(i)}$'s given the $x^{(i)}$'s), this can also be written
$$ \begin{array}{lcl} \mathscr{L}(\theta) & = & \prod\limits^{m}_{i=1} p(y^{(i)}|x^{(i)}; \theta)\\ & = & \prod\limits^{m}_{i=1} \dfrac{1}{\sqrt{2\pi}\sigma} \exp \Big( -\dfrac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2} \Big) \end{array} $$Now, given this probabilistic model relating the $y^{(i)}$'s and the $x^{(i)}$'s, what is a reasonable way of choosing our best guess of the parameters $\theta$? The principal of maximum likelihood (MLE) says that we should should choose $\theta$ so as to make the data as high probability as possible. I.e., we should choose $\theta$ to maximize $\mathscr{L}(\theta)$.
Instead of maximizing $\mathscr{L}(\theta)$, we can also maximize any strictly increasing function of $\mathscr{L}(\theta)$. In particular, the derivations will be a bit simpler if we instead maximize the log likelihood $ℓ(\theta)$:
$$ \begin{array}{lcl} ℓ(\theta) & = & \log \mathscr{L}(\theta)\\ & = & \log \prod\limits^{m}_{i=1} \dfrac{1}{\sqrt{2\pi}\sigma} \exp \Big( -\dfrac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2} \Big)\\ & = & \sum\limits^{m}_{i=1} \log \dfrac{1}{\sqrt{2\pi}\sigma} \exp \Big( -\dfrac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2} \Big)\\ & = & m\log\dfrac{1}{\sqrt{2\pi}\sigma} - \dfrac{1}{\sigma^2} \cdot \dfrac{1}{2} \sum\limits^{m}_{i=1} \big(y^{(i)} - \theta^T x^{(i)}\big)^2 \end{array} $$Hence, maximizing $ℓ(\theta)$ gives the same answer as minimizing
$$\dfrac{1}{2} \sum^{m}_{i=1} \big(y^{(i)} - \theta^T x^{(i)}\big)^2,$$which we recognize to be $J(\theta)$, our original least-squares cost function.
To summarize: Under the previous probabilistic assumptions on the data, least-squares regression corresponds to finding the maximum likelihood estimate of $\theta$. This is thus one set of assumptions under which least-squares regression can be justified as a very natural method that’s just doing maximum likelihood estimation. (Note however that the probabilistic assumptions are by no means $necessary$ for least-squares to be a perfectly good and rational procedure, and there may—and indeed there are—other natural assumptions that can also be used to justify it.)
Note also that, in our previous discussion, our final choice of $\theta$ did not depend on what was $\sigma^2$, and indeed we’d have arrived at the same result even if $\sigma^2$ were unknown. We will use this fact again later, when we talk about the exponential family and generalized linear models.
Q & A
Q: what’s the difference between likelihood and probability?
A: The likelihood of the parameters is exactly the same thing as the probability of the data, but the reason we sometimes talk about likelihood, and sometimes talk of probability is, um, if you think of the training set the data as a fixed thing, and then varying parameters theta, then I’m going to use the term likelihood. Whereas if you view the parameters theta as fixed and maybe varying the data, I’m gonna say probability, right?
Q: why is epsilon i Gaussian?
A: So, uh, uh, turns out because of central limit theorem, uh, from statistics, uh, most error distributions are Gaussian, right? If there’s an era that’s made up of lots of little noise sources which are not too correlated, then by central limit theorem it will be Gaussian. So if you think that, most perturbations are, the mood of the seller, what’s the school district, you know, what’s the weather like, or access to transportation, and all of these sources are not too correlated, and you add them up then the distribution will be Gaussian. So you can use the central limit theorem, I think the Gaussian has become a default noise distribution. But for things where the true noise distribution is very far from Gaussian, uh, this model does do that as well. And in fact, for when you see generalized linear models on Wednesday, you see how to generalize all of these algorithms to very different distributions like Poisson, and so on.
¶Logistic regression
Lets now talk about the classification problem. This is just like the regression problem, except that the values $y$ we now want to predict take on only a small number of discrete values. For now, we will focus on the binary classification problem in which $y$ can take on only two values, $0$ and $1$. (Most of what we say here will also generalize to the multiple-class case.) For instance, if we are trying to build a spam classifier for email, then $x^{(i)}$ may be some features of a piece of email, and $y$ may be $1$ if it is a piece of spam mail, and $0$ otherwise. $0$ is also called the negative class, and 1 the positive class, and they are sometimes also denoted by the symbols “$-$” and “$+$.” Given $x^{(i)}$, the corresponding $y^{(i)}$ is also called the label for the training example.
We could approach the classification problem ignoring the fact that $y$ is discrete-valued, and use our old linear regression algorithm to try to predict $y$ given $x$. However, it is easy to construct examples where this method performs very poorly. Intuitively, it also doesn’t make sense for $h_\theta(x)$ to take values larger than $1$ or smaller than $0$ when we know that $y \in \{0, 1\}$.
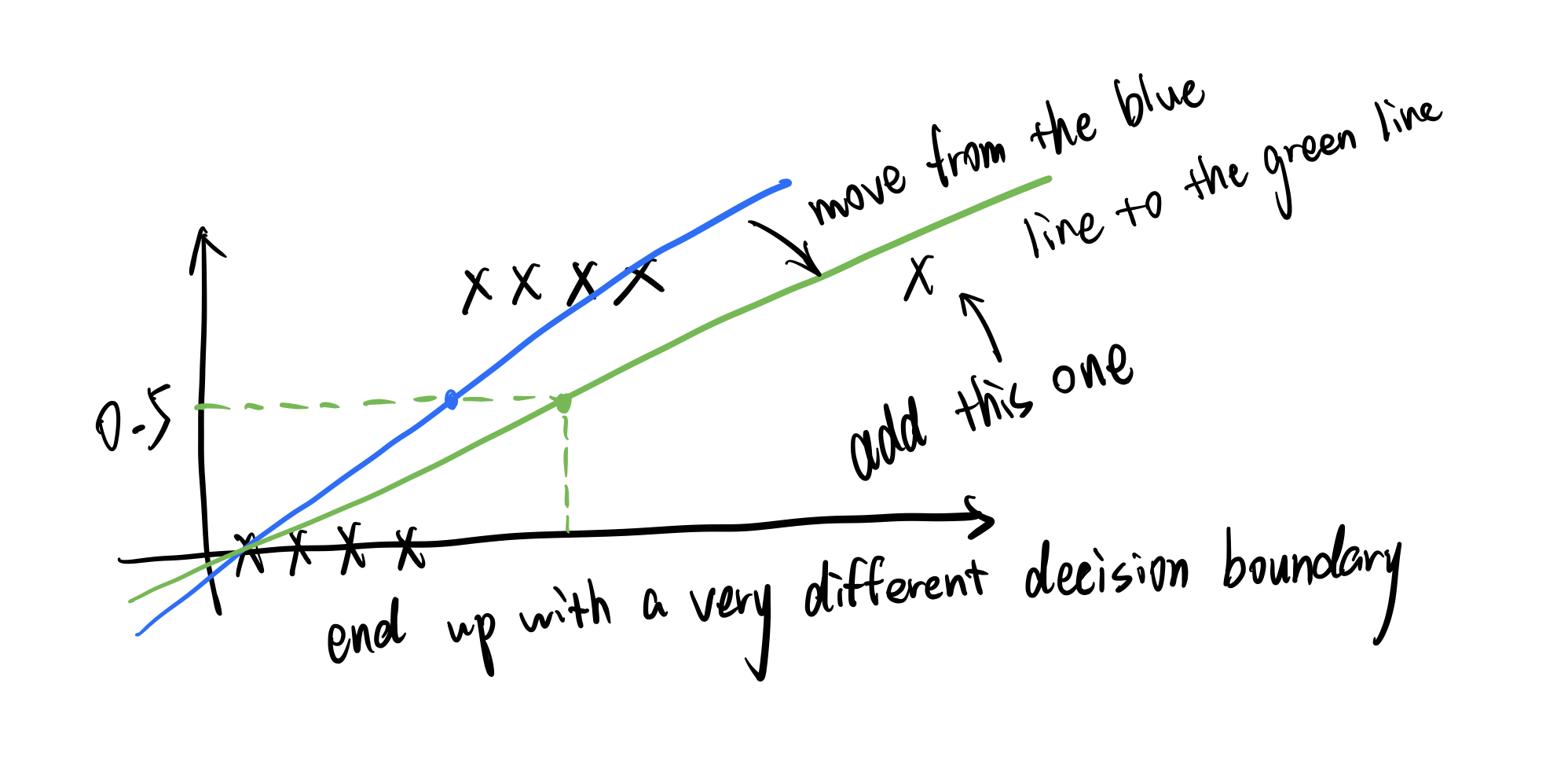
To fix this, lets change the form for our hypotheses $h_\theta(x)$. We will choose
$$h_\theta(x) = g(\theta^T x) = \dfrac{1}{1 + e^{-\theta^T x}},$$where
$$g(z) = \dfrac{1}{1 + e^{-z}}$$is called the logistic function or the sigmoid function. Here is a plot showing $g(z)$:
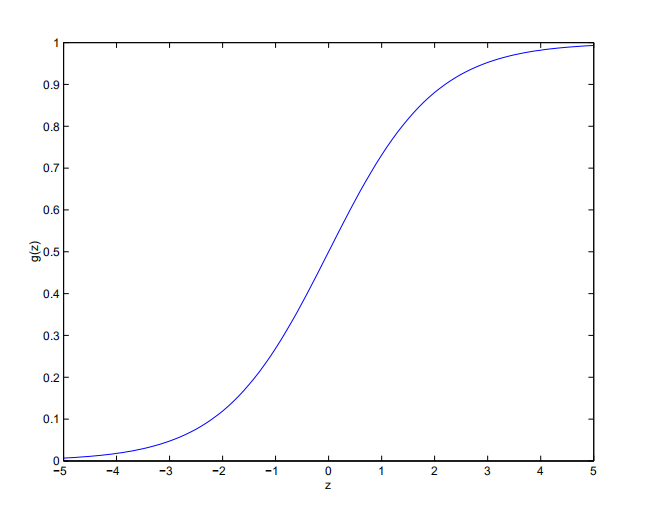
Notice that $g(z)$ tends towards $1$ as $z \rightarrow \infty$, and $g(z)$ tends towards $0$ as $z \rightarrow −\infty$. Moreover, $g(z)$, and hence also $h(x)$, is always bounded between $0$ and $1$. As before, we are keeping the convention of letting $x_0 = 1$, so that $\theta^T x = \theta_0 + \sum\limits^{n}_{j=1} \theta_jx_j$ .
For now, lets take the choice of $g$ as given. Other functions that smoothly increase from $0$ to $1$ can also be used, but for a couple of reasons that we’ll see later (when we talk about GLMs, and when we talk about generative learning algorithms), the choice of the logistic function is a fairly natural one. Before moving on, here’s a useful property of the derivative of the sigmoid function, which we write a $g′$:
$$ \begin{array}{lcl} g'(z) & = & \dfrac{\mathrm{d}}{\mathrm{d}z} \dfrac{1}{1 + e^{-z}}\\ & = & \dfrac{1}{(1 + e^{-z})^2} (e^{-z})\\ & = & \dfrac{1}{(1 + e^{-z})} \cdot \Big( 1 - \dfrac{1}{(1 + e^{-z})}\Big)\\ & = & g(z)(1 - g(z)). \end{array} $$So, given the logistic regression model, how do we fit $\theta$ for it? Following how we saw least squares regression could be derived as the maximum likelihood estimator under a set of assumptions, lets endow our classification model with a set of probabilistic assumptions, and then fit the parameters via maximum likelihood.
Let us assume that
$$P(y=1~|~x; \theta) = h_\theta(x)$$ $$P(y=0~|~x; \theta) = 1 - h_\theta(x)$$Note that this can be written more compactly as
$$P(y~|~x; \theta) = (h_\theta(x))^y (1 - h_\theta(x))^{1-y}$$Assuming that the $m$ training examples were generated independently, we can then write down the likelihood of the parameters as
$$ \begin{array}{lcl} \mathscr{L}(\theta) & = & p(\vec{y}~|~X; \theta)\\ & = & \prod\limits^{m}_{i=1} p(y^{(i)}~|~x^{(i)}; \theta)\\ & = & \prod\limits^{m}_{i=1} \big(h_\theta(x^{(i)})\big)^{y^{(i)}} \big(1 - h_\theta(x^{(i)})\big)^{1-y^{(i)}} \end{array} $$As before, it will be easier to maximize the log likelihood:
$$ \begin{array}{lcl} ℓ(\theta) & = & \log \mathscr{L}(\theta)\\ & = & \sum\limits^{m}_{i=1} y^{(i)} \log h(x^{(i)}) + (1 - y^{(i)}) \log (1 - h(x^{(i)})) \end{array} $$How do we maximize the likelihood? Similar to our derivation in the case of linear regression, we can use gradient ascent. Written in vectorial notation, our updates will therefore be given by
$$\theta := \theta + \alpha \nabla_\thetaℓ(\theta).$$(Note the positive rather than negative sign in the update formula, since we’re maximizing, rather than minimizing, a function now.) Lets start by working with just one training example $(x, y)$, and take derivatives to derive the stochastic gradient ascent rule:
$$ \begin{array}{lcl} \dfrac{\partial}{\partial \theta_j} ℓ(\theta) & = & \Big( y \dfrac{1}{g(\theta^T x)} - (1-y) \dfrac{1}{1 - g(\theta^T x)}\Big) \dfrac{\partial}{\partial \theta_j}g(\theta^T x)\\ & = & \Big( y \dfrac{1}{g(\theta^T x)} - (1-y) \dfrac{1}{1 - g(\theta^T x)}\Big)g(\theta^T x)(1 - g(\theta^T x)) \dfrac{\partial}{\partial \theta_j} \theta^T x\\ & = & \big( y (1 - g(\theta^T x)) - (1-y) g(\theta^T x)\big) x_j\\ & = & (y - h_\theta(x)) x_j \end{array} $$Above, we used the fact that $g′(z) = g(z)(1 - g(z))$. This therefore gives us the stochastic gradient ascent rule
$$\theta := \theta + \alpha \big( y^{(i)} - h_\theta(x^{(i)}) \big)x_j^{(i)}$$If we compare this to the LMS update rule, we see that it looks identical; but this is not the same algorithm, because $h_\theta(x^{(i)})$ is now defined as a non-linear function of $\theta^T x^{(i)}$. Nonetheless, it’s a little surprising that we end up with the same update rule for a rather different algorithm and learning problem. Is this coincidence, or is there a deeper reason behind this? We’ll answer this when get to GLM models.
¶Digression: The perceptron learning algorithm
For further information, please refer to the relevant books.
¶Newton’s method
Returning to logistic regression with $g(z)$ being the sigmoid function, lets now talk about a different algorithm for minimizing $ℓ(\theta)$.
To get us started, lets consider Newton’s method for finding a zero of a function. Specifically, suppose we have some function $f$ : $\mathbb{R} \longmapsto \mathbb{R}$, and we wish to find a value of $\theta$ so that $f(\theta) = 0$. Here, $\theta \in \mathbb{R}$ is a real number. Newton’s method performs the following update:
$$\theta := \theta - \dfrac{f(\theta)}{f'(\theta)}.$$This method has a natural interpretation in which we can think of it as approximating the function f via a linear function that is tangent to $f$ at the current guess $\theta$, solving for where that linear function equals to zero, and letting the next guess for $\theta$ be where that linear function is zero.
Here’s a picture of the Newton’s method in action:
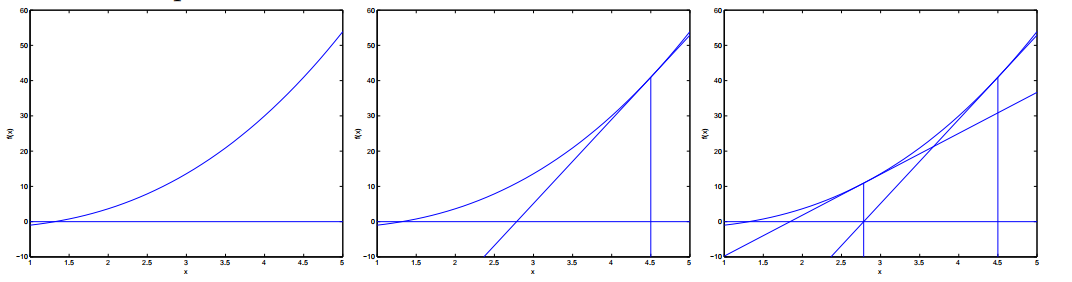
In the leftmost figure, we see the function $f$ plotted along with the line $y = 0$. We’re trying to find $\theta$ so that $f(\theta) = 0$; the value of $\theta$ that achieves this is about $1.3$. Suppose we initialized the algorithm with $\theta = 4.5$. Newton’s method then fits a straight line tangent to $f$ at $\theta = 4.5$, and solves for the where that line evaluates to $0$. (Middle figure.) This give us the next guess for $\theta$, which is about $2.8$. The rightmost figure shows the result of running one more iteration, which the updates $\theta$ to about $1.8$. After a few more iterations, we rapidly approach $\theta = 1.3$.
Newton’s method gives a way of getting to $f(\theta) = 0$. What if we want to use it to maximize some function $ℓ$? The maxima of $ℓ$ correspond to points where its first derivative $ℓ’(\theta)$ is zero. So, by letting $f(\theta) = ℓ’(\theta)$, we can use the same algorithm to maximize $ℓ$, and we obtain update rule:
$$\theta := \theta - \dfrac{ℓ'(\theta)}{ℓ''(\theta)}.$$(Something to think about: How would this change if we wanted to use Newton’s method to minimize rather than maximize a function?)
Lastly, in our logistic regression setting, $\theta$ is vector-valued, so we need to generalize Newton’s method to this setting. The generalization of Newton’s method to this multidimensional setting (also called the Newton-Raphson method) is given by
$$\theta := \theta - H^{-1} \nabla_\thetaℓ(\theta).$$Here, $\nabla_\theta ℓ(\theta)$ is, as usual, the vector of partial derivatives of $ℓ(\theta)$ with respect to the $\theta_i’s$; and $H$ is an $n$-by-$n$ matrix (actually, $n + 1$-by-$n + 1$, assuming that we include the intercept term) called the Hessian, whose entries are given by
$$H_{ij} = \dfrac{\partial^2 ℓ(\theta)}{\partial \theta_i \partial \theta_j}$$Newton’s method typically enjoys faster convergence than (batch) gradient descent, and requires many fewer iterations to get very close to the minimum. One iteration of Newton’s can, however, be more expensive than one iteration of gradient descent, since it requires finding and inverting an $n$-by-$n$ Hessian; but so long as $n$ is not too large, it is usually much faster overall. When Newton’s method is applied to maximize the logistic regression log likelihood function $ℓ(\theta)$, the resulting method is also called Fisher scoring.

