Convolutional Neural Networks. Andrew Ng.
Convolutional Neural Networks. Part 1.
Part 1.
Convolutional Neural Networks. Yann LeCun interview.
¶Computer vision
¶Deep Learning for computer vision
- self-driving car
- face recognition
- show the most attractive or the most relevant pictures
- enable new types of art to be created
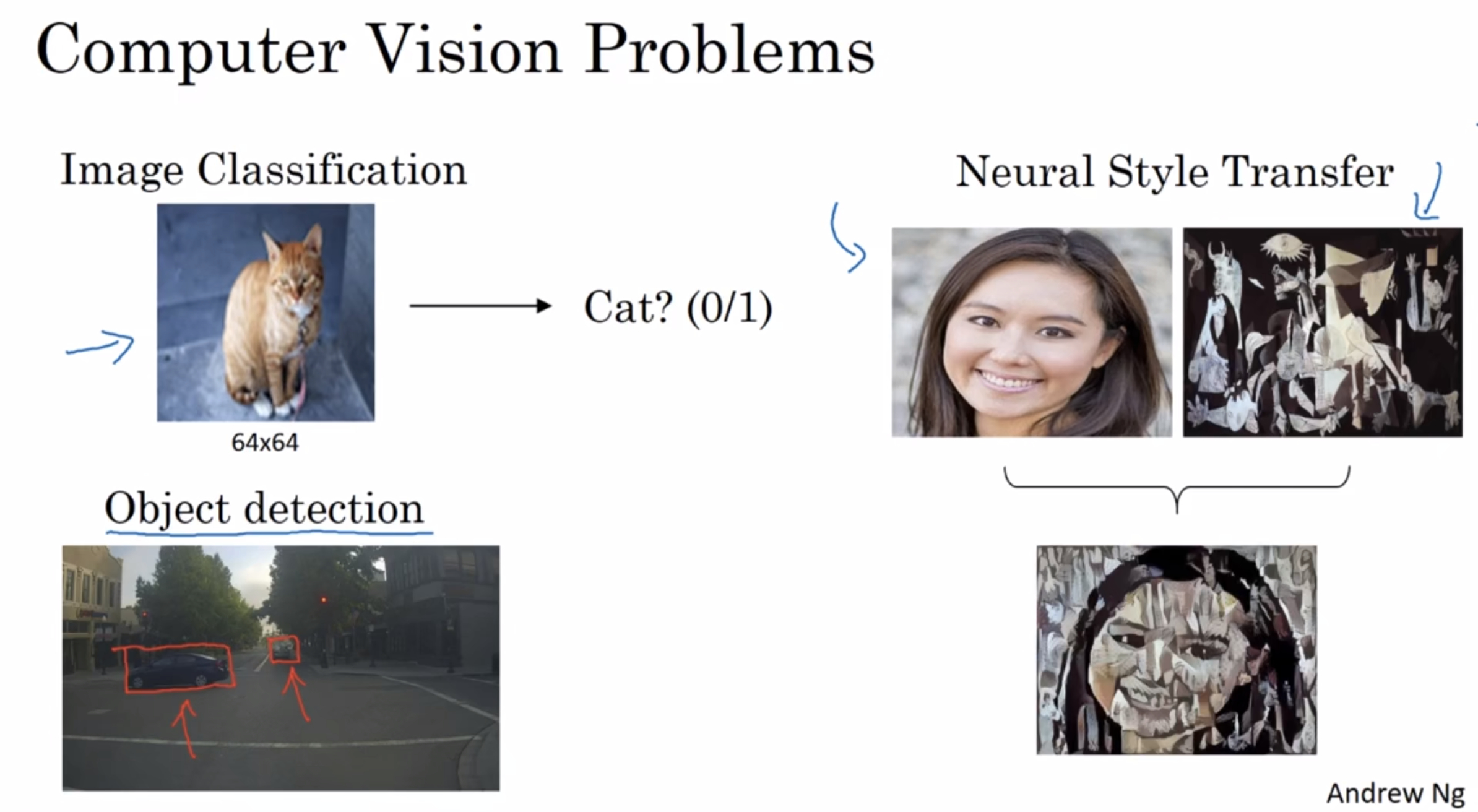
¶Computer Vision Problems
- Image Classification
- Object detection
- Neural Style Transfer
¶Deep Learning on large images
standard or fully connected network : billions of parameters (very large)
- it is difficult to get enough data to prevent a neural network from overfitting
- the computational requirements and the momory requirements to train a neural network with billions of parameters is just a bit infeasible
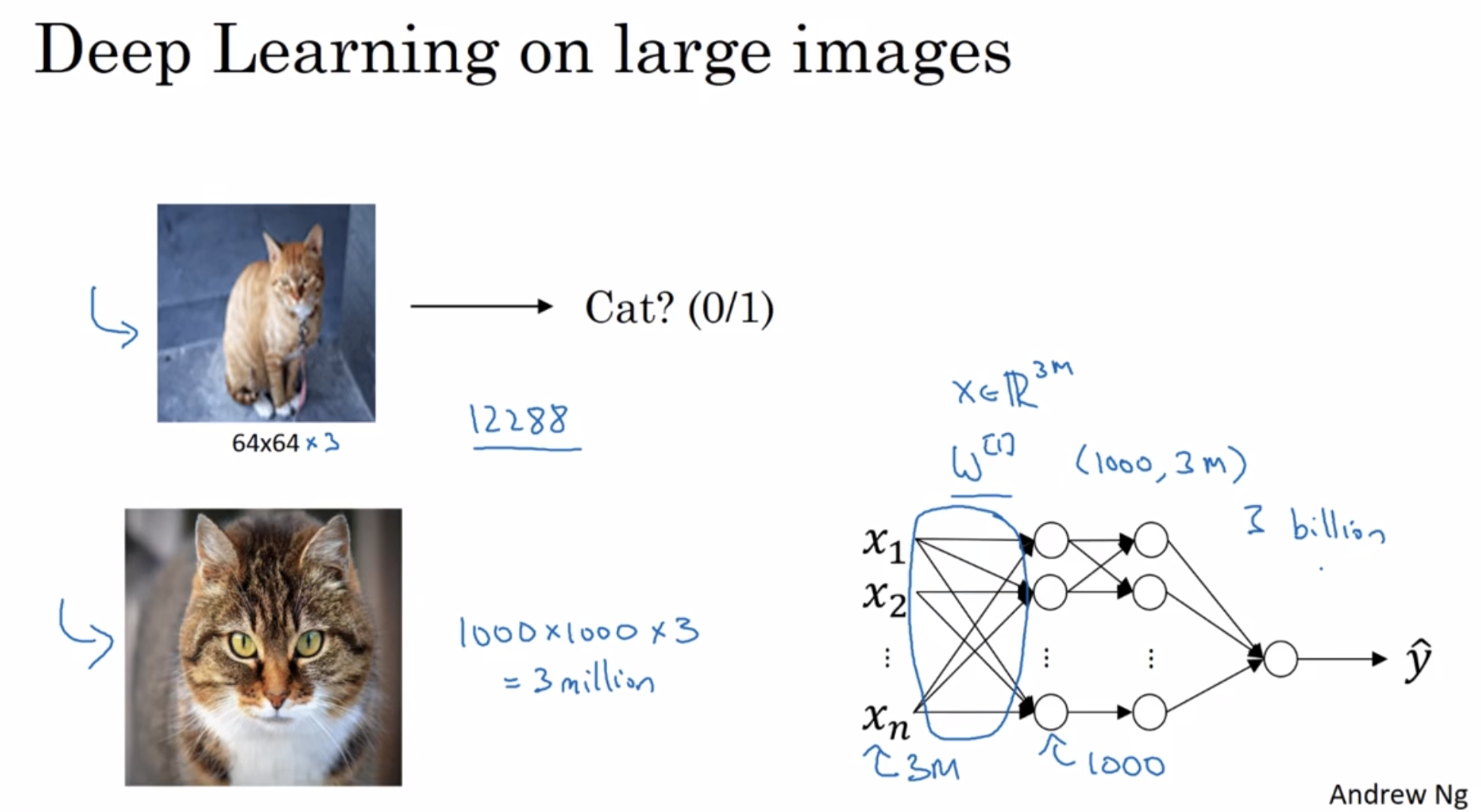
For computer vision applications, you don’t want to be stuck using only tiny little images, you want to use large images. To do that, you need to better implement the convolution operation, which is one of the fundamental building blocks of convolutional neural networks.
¶Edge detection example
see how the convolution operation works
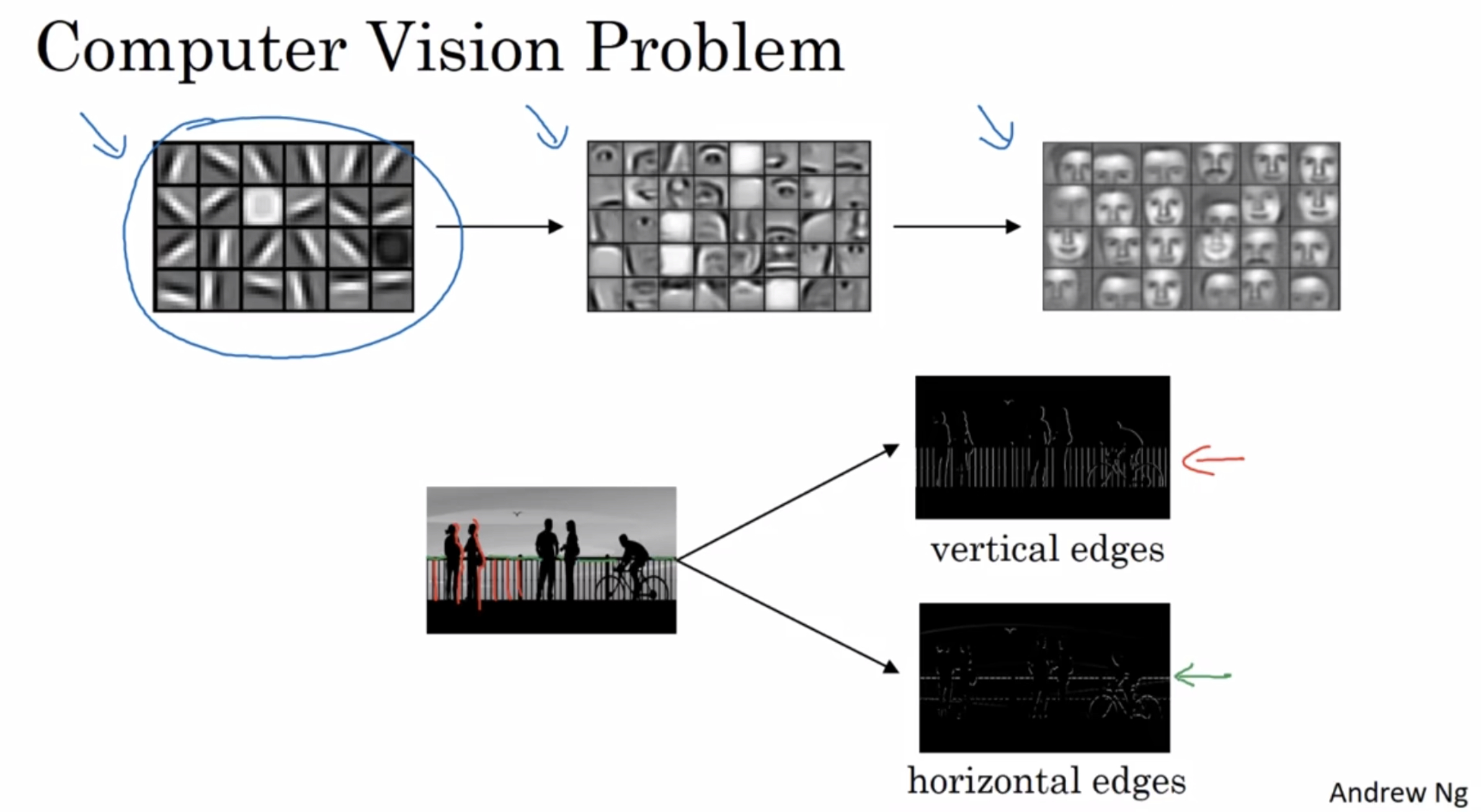
Given a picture like that for a computer to figure out what are the objects in this picture, and the first thing you might do is maybe detect vertical edges and the horizontal edges in this image.
¶Vertical edge detection
How do you detect edges in image like this?
Here is a 6 by 6 grayscale image.
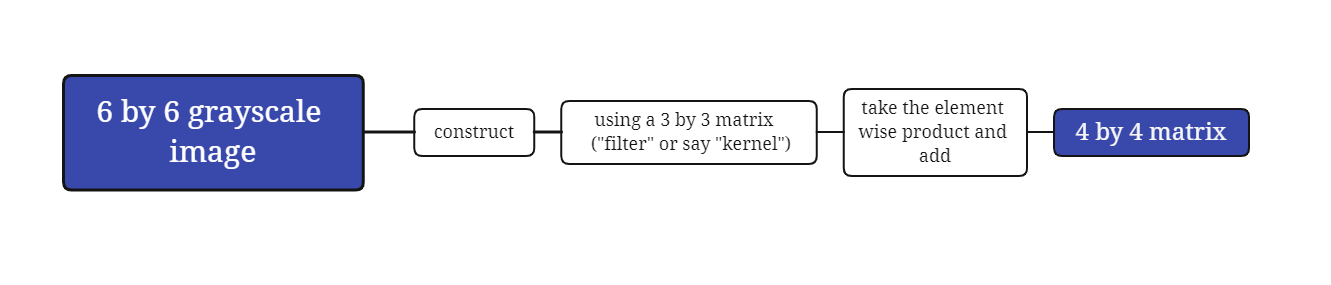
And this turns out to be a vertical edge detector.
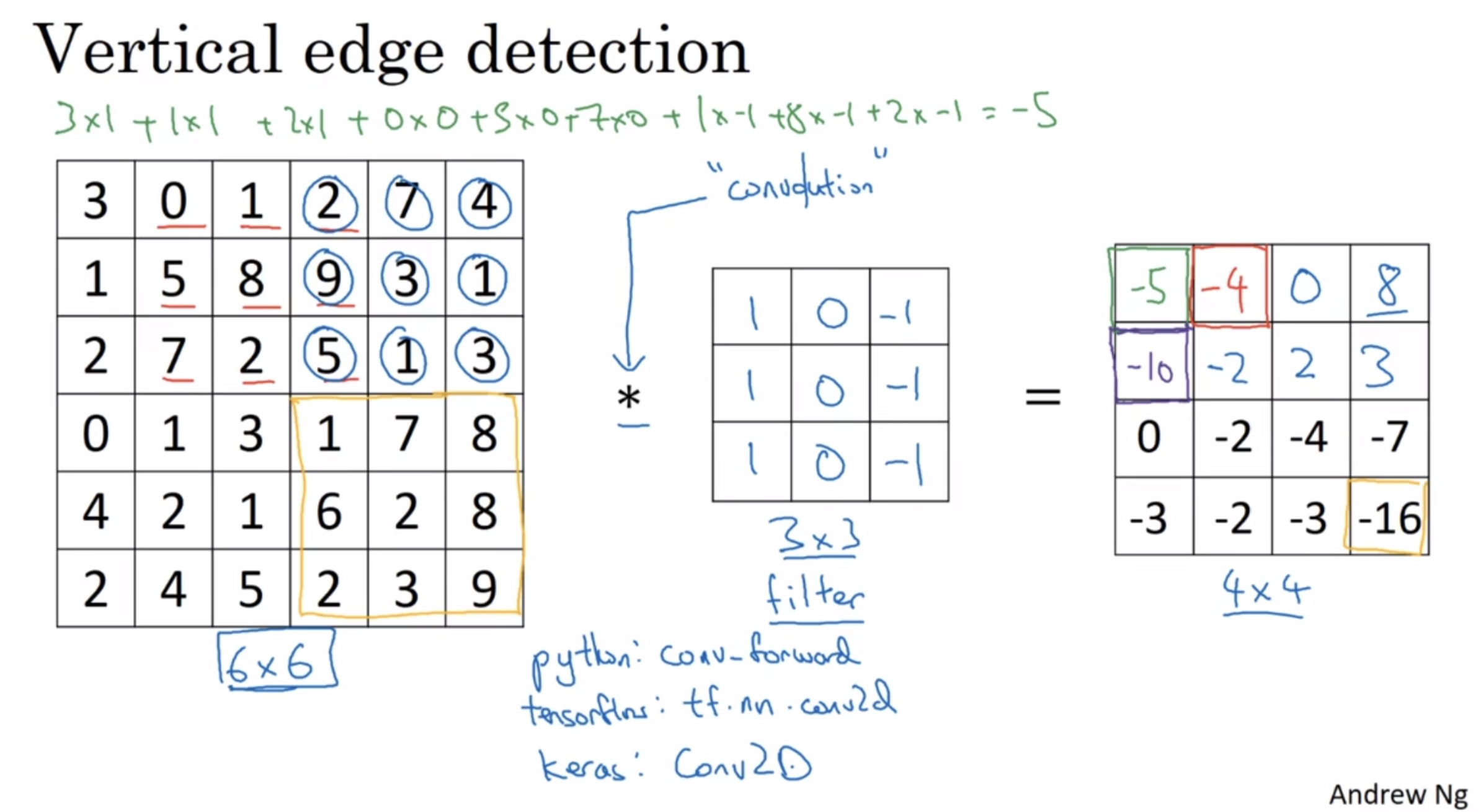
Why is this doing vertical edge detection?
The lighter region right in the middle corresponds to this having detected this vertical edge down the middle of your 6 by 6 image.

In this example, this bright region in the middle is just the output images way of saying that it looks like there is a strong vertical edge right down the middle of the image.
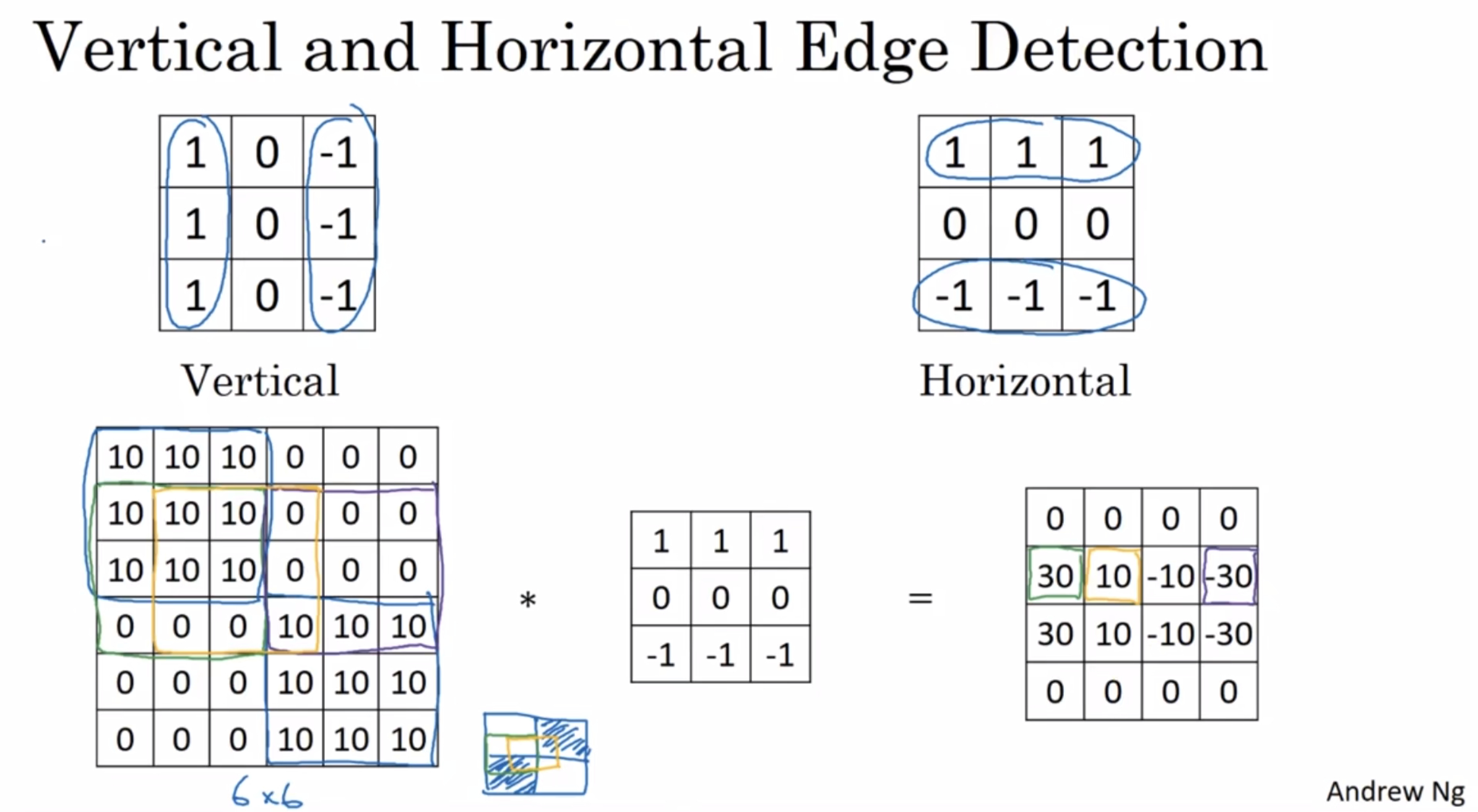
¶More edge detection
the difference between positive and negative edges
that is the difference between light to dark versus dark to light edge transitions
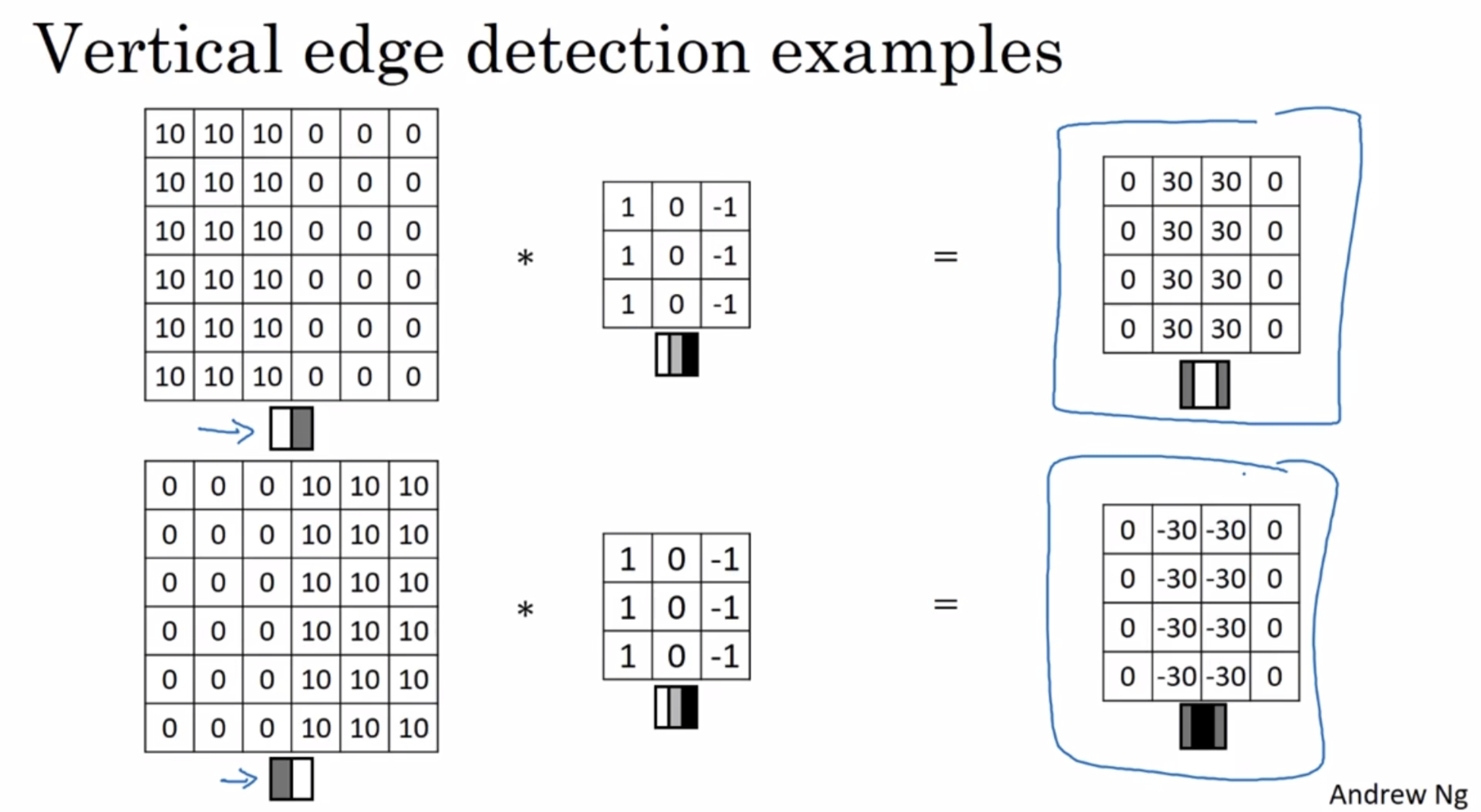
If you don’t care which of these two cases it is, you could take absolute values of this output matrix.
- sobel filter:
puts a little bit more weight to the central row
more robust - scharr filter
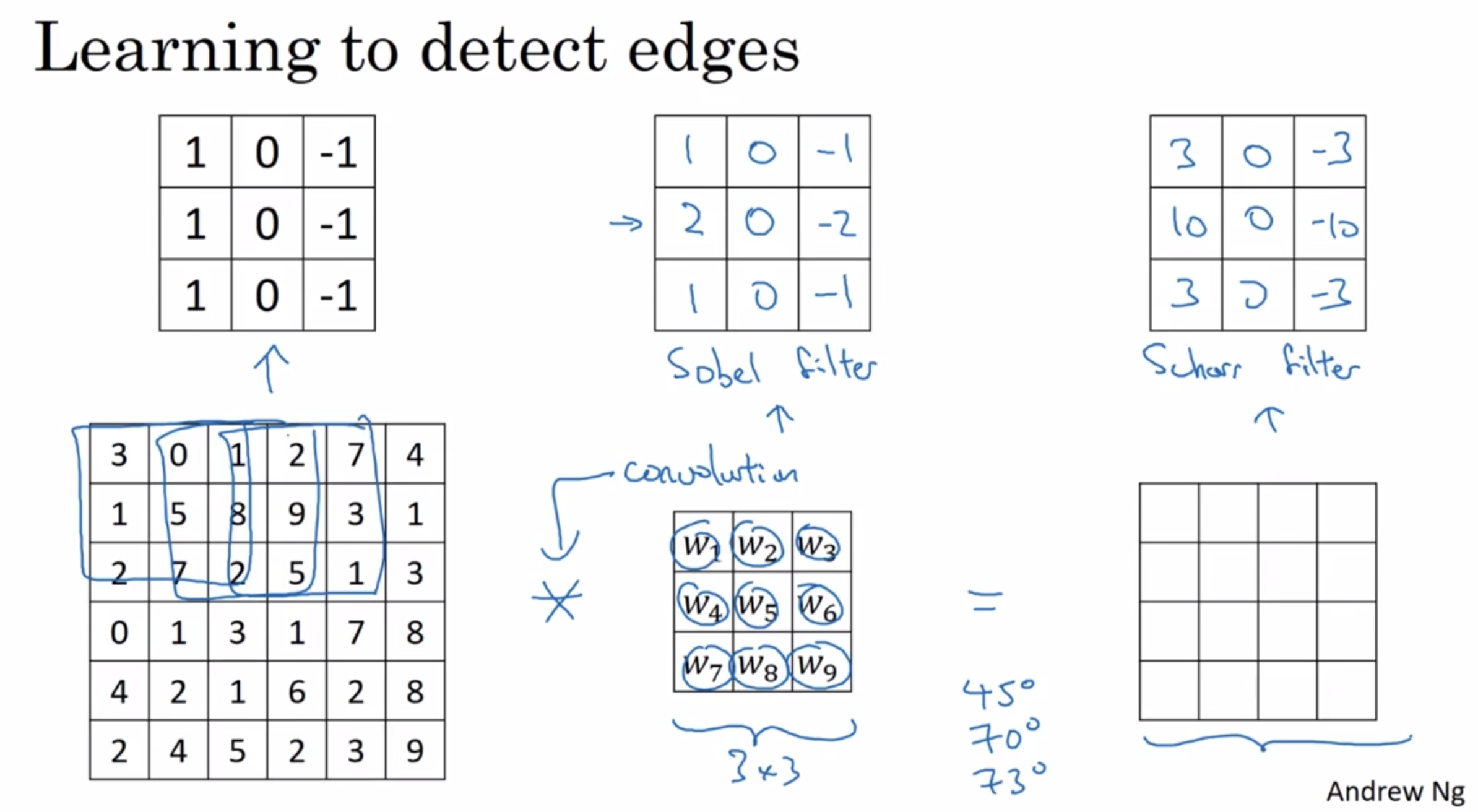
just learn them and treat the nine numbers of this matrix as parameters, then learn using back propagation
so just letting all of these numbers be parameters and learning them automatically from data, we find that neural networks can actually learn low level features such as edges, even more robustly than computer vision researchers are generally able to code up these things by hand.
how to use padding as well as different strides for conv
¶Padding
In order to build deep neural networks one modification to the basic convolutional operation that you nend to really use is padding.
n by n image / f by f filter
the dimension of the output will be (n-f+1) by (n-f+1)
two downsides to this:
- getting small
- lost information near the edge of the image
solution: pad the image using 0 before the convolution operation
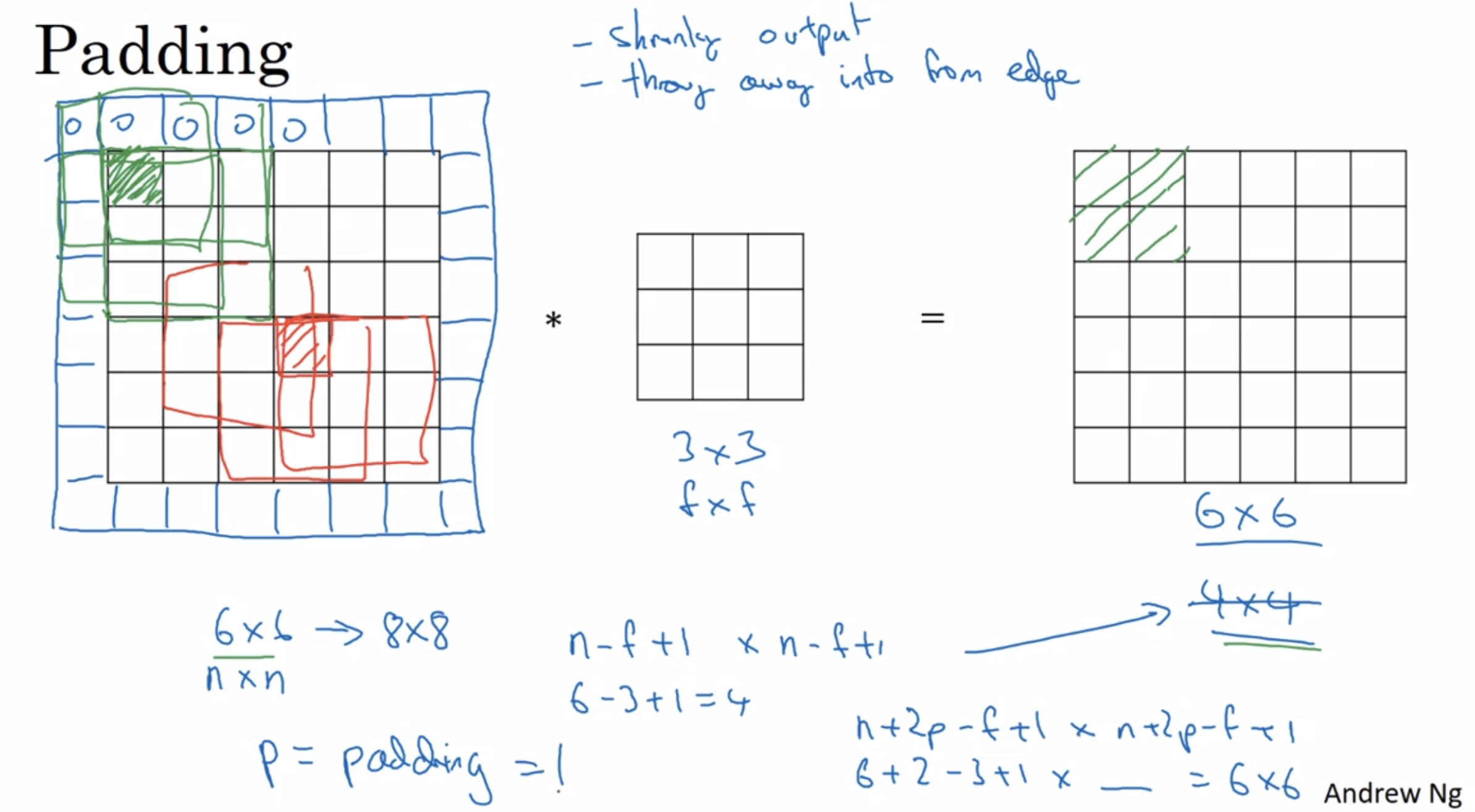
then the output becomes (n+2p-f+1) by (n+2p-f+1)
counting less the information from the edge of the corner or the edge of the image is reduced

in CV, f is usually odd:
- gives a natural padding region
- nice to have a distinguisher (central position)
recommend just use odd number filters
¶Strided convolutions
Strided convolutions is another piece of the basic buliding block of convolutions as used in Convolutional Neural Networks.
We are going to do the Conv with a stride of two.
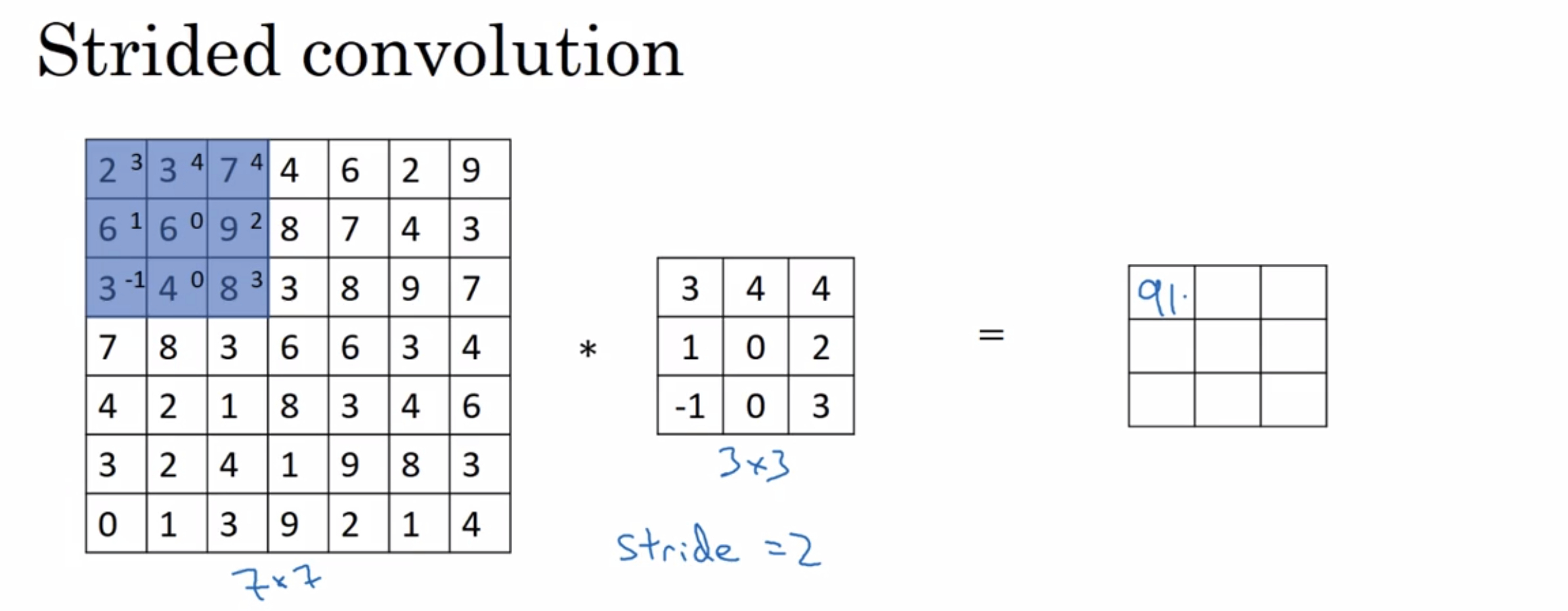
step over by two steps
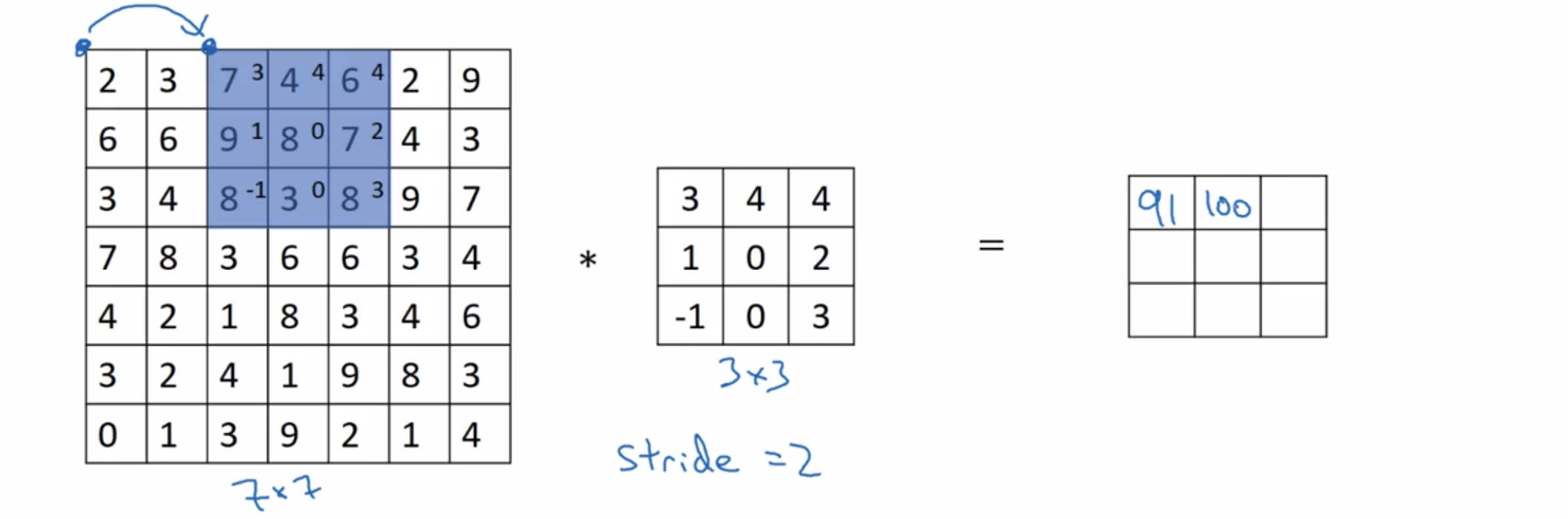
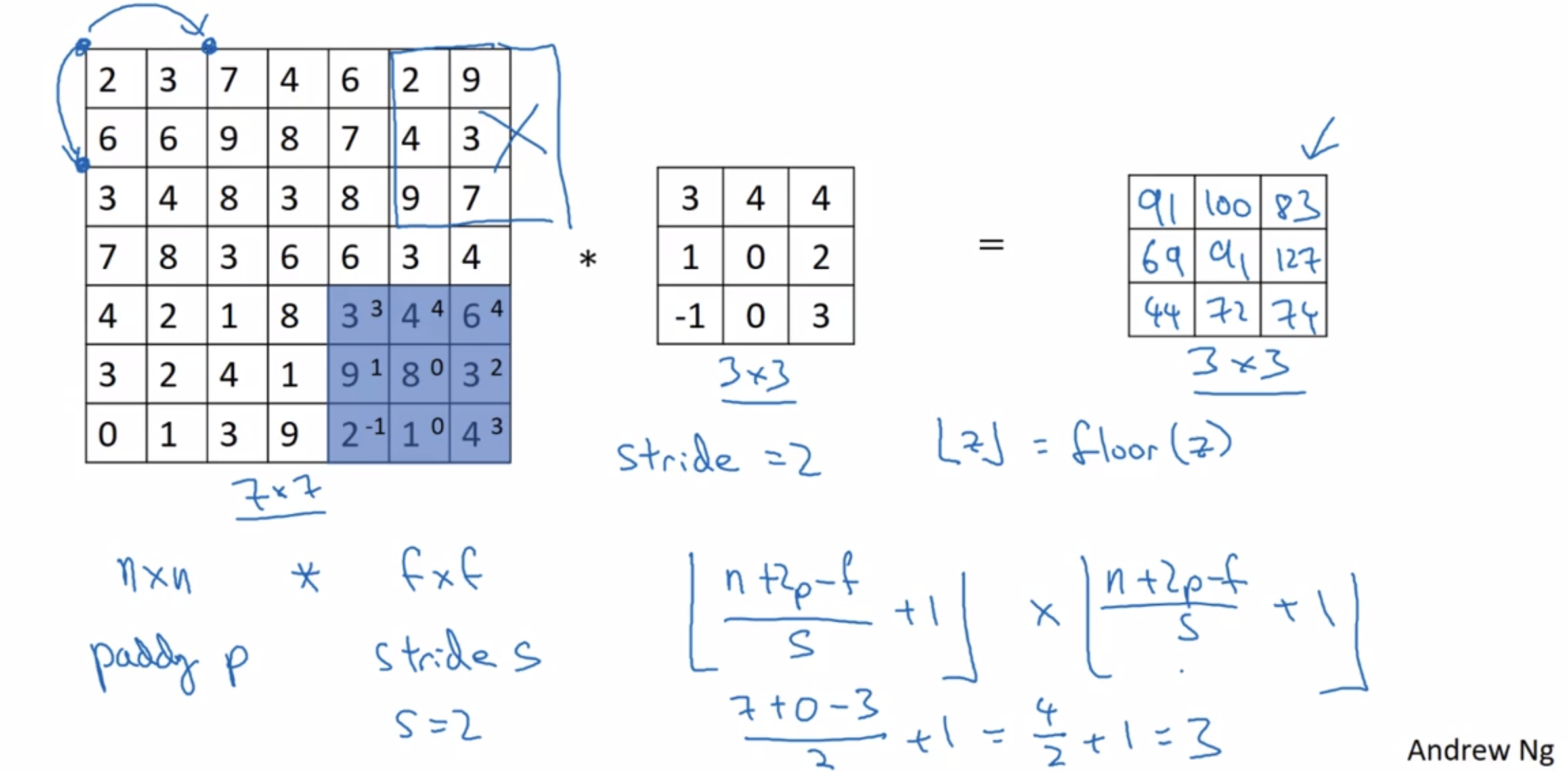

¶cross-correlation and convolution
we’ve skipped the flipping operation.

Just to summarize, by convention in machine learning, we usually do not bother with this skipping operation, and technically, this operation is maybe better called cross-correlation but most of the deep learning literature just calls it the convolution operator.
¶Convolutions over volumes
You’ve seen how Conv over 2D images works. Now, let’s see how you can implement Conv over three dimensional volumes.
Let’s start with an example.
Let’s say you want to detect features not just in a gray scale image, but in a RGB image.
Three here responds to the three color channels and you could think of this as a stack of three six by six images.
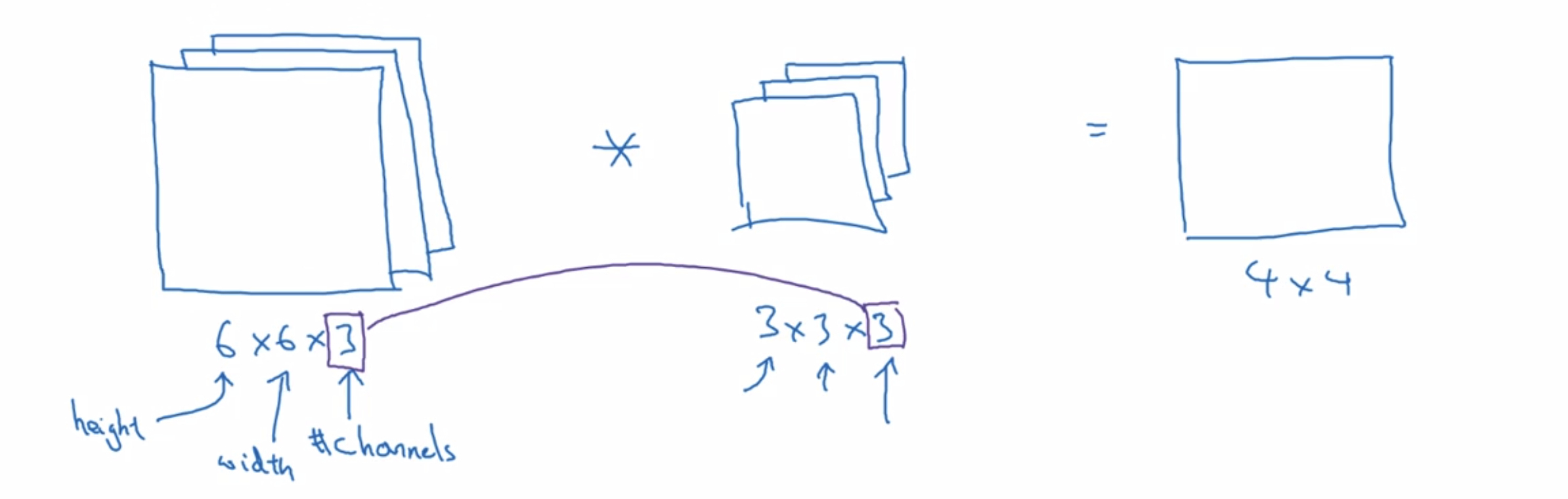
Let’s go through in detail how this works.
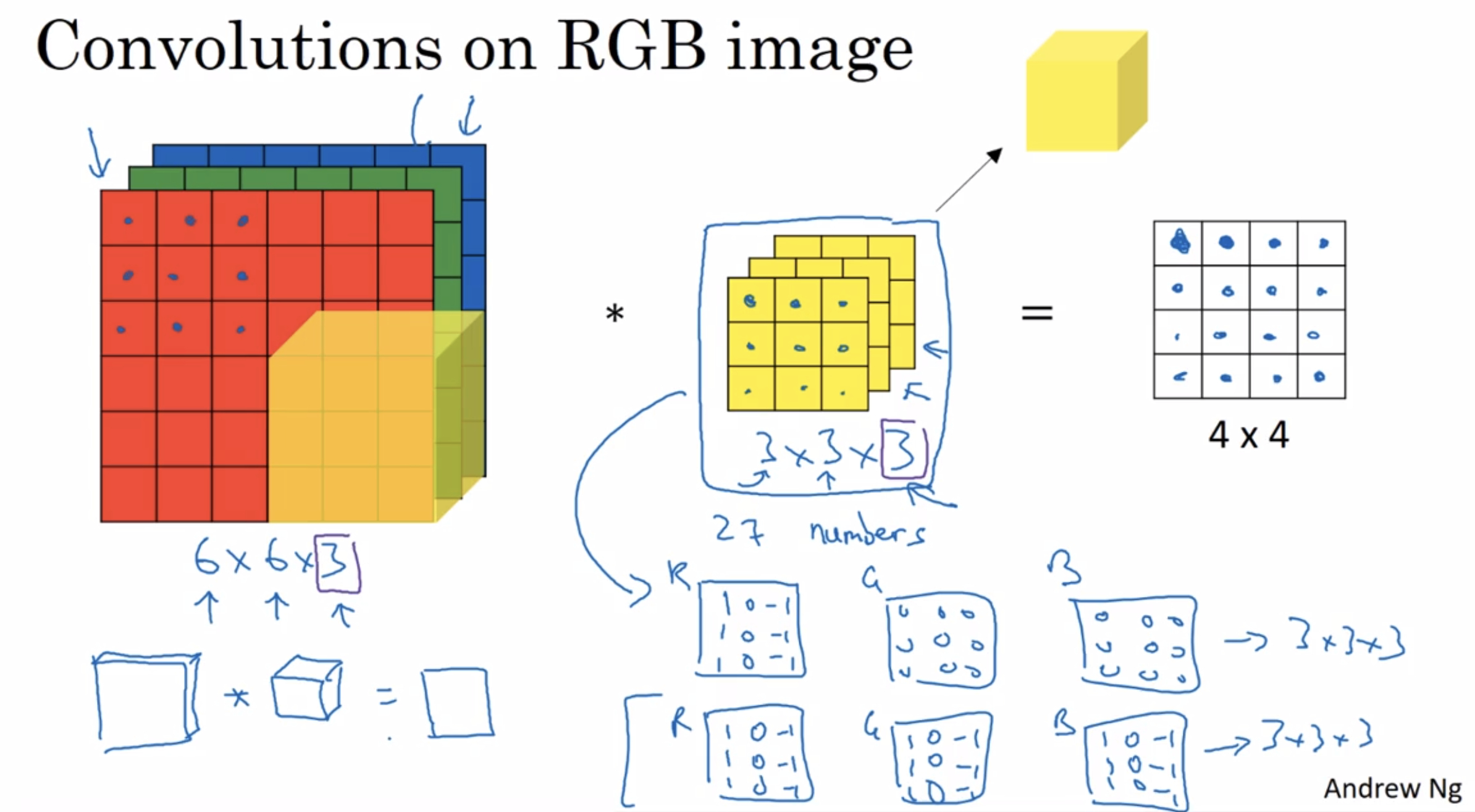
if you want to detect edges in the red channel of the image
you could set the first filter as a vertical edge detector, and have the green / blue channel be all zeros
alternatively, if you don’t care what color the vertical edge is in
then you might have a filter that’s like the second one
what if we don’t just wanted to detect vertical edges?
in other words, what if you want to use multiple filters at the same time?
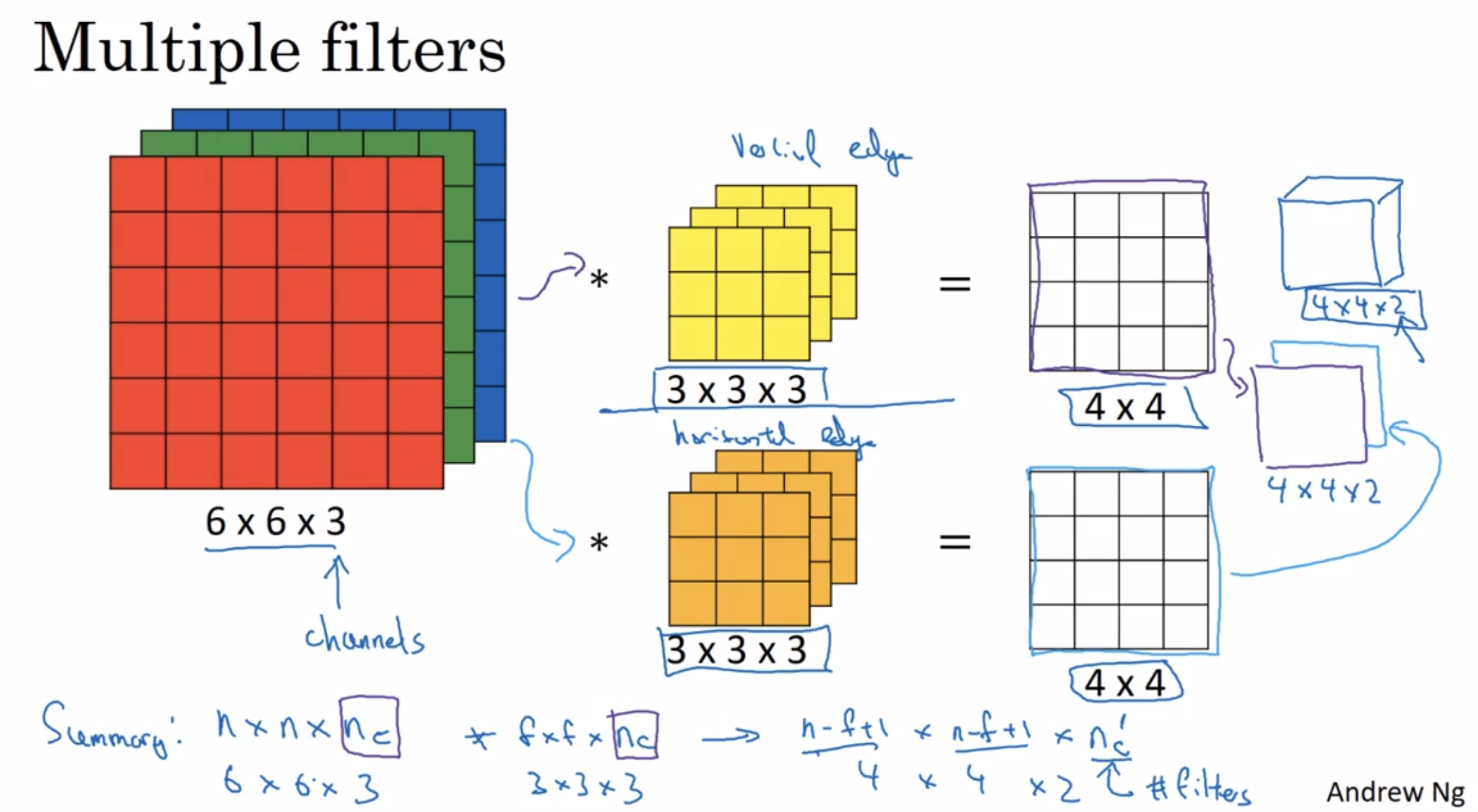
¶One layer of a convolutional network
Get now ready to see how to build one layer of a convolutional network.
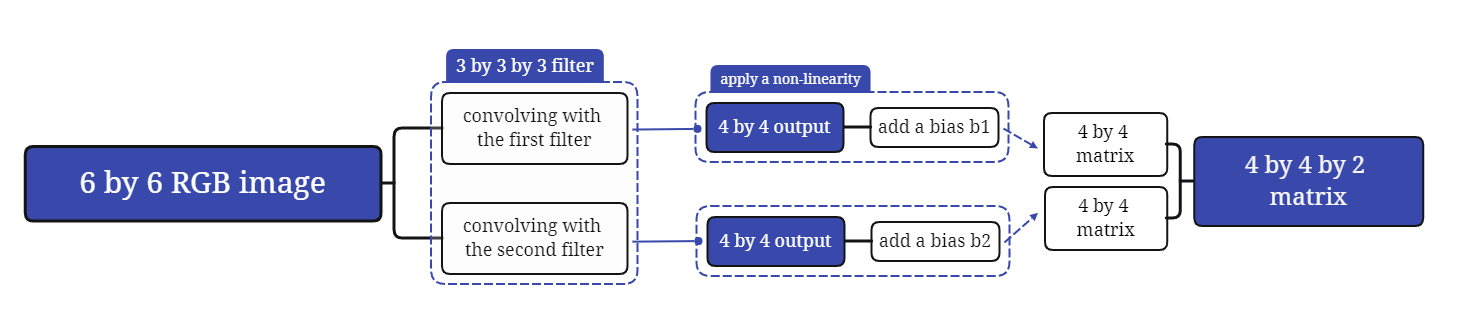
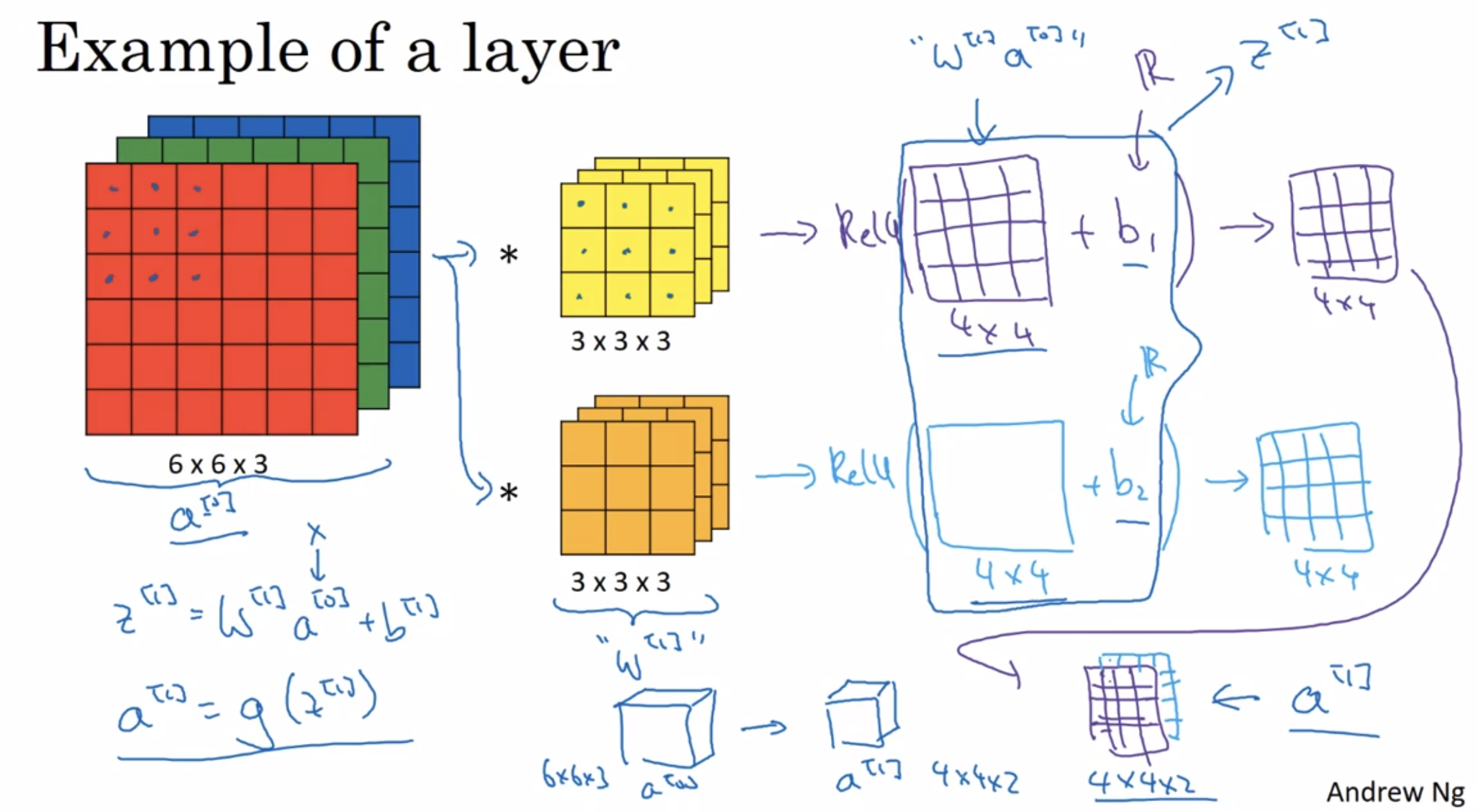

The key point is just how one layer of how convolution neural network works.
¶A simple convolution network example
Now let’s go through a concrete example of a deep convolutional neural network.
Let’s say you have an image, and you want to do image classification, or image recognition. And you want to take an image as input X, and decide this is a cat or not, so it’s a classification problem. Let’s build an example of a ConvNet you could use for this task.

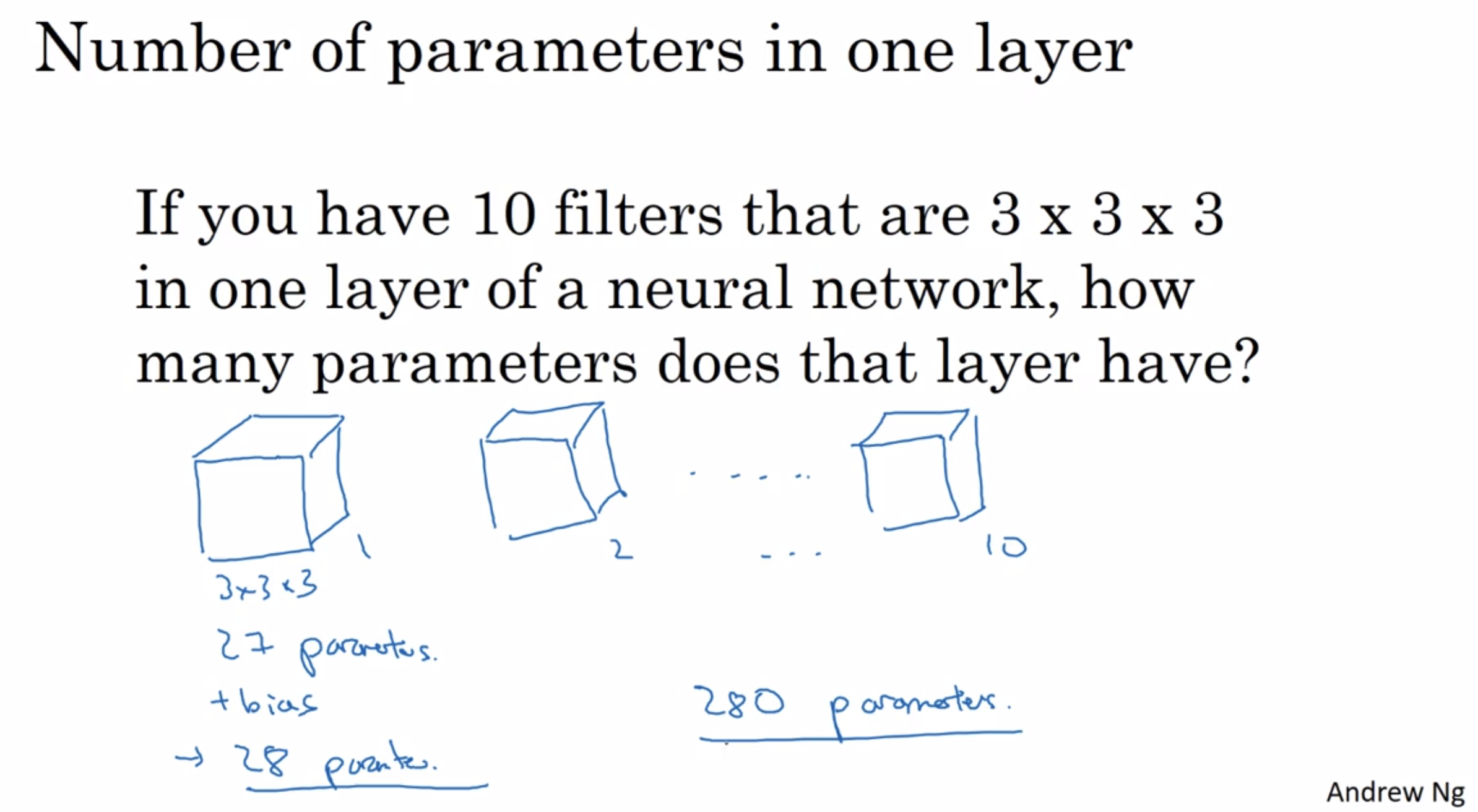
A lot of the work in designing convolutional neural net is selecting hyperparameters like these, deciding what’s the total size? What’s the stride? What’s the padding and how many filters are used?
¶Types of layer in a convolutional network
- Convolution ( CONV )
- Pooling ( POOL )
- Fully connected ( FC )
Fortunately pooling layers and fully connected layers are a bit simpler than convolutional layers to define.
¶Pooling layers
Other than convolutional layers, ConvNets often also use pooling layers to reduce the size of the representation, to speed the computation, as well as make some of the features that detects a bit more robust.
Let’s go through an example of pooling and talk about why you might want to do this.
¶Max pooling
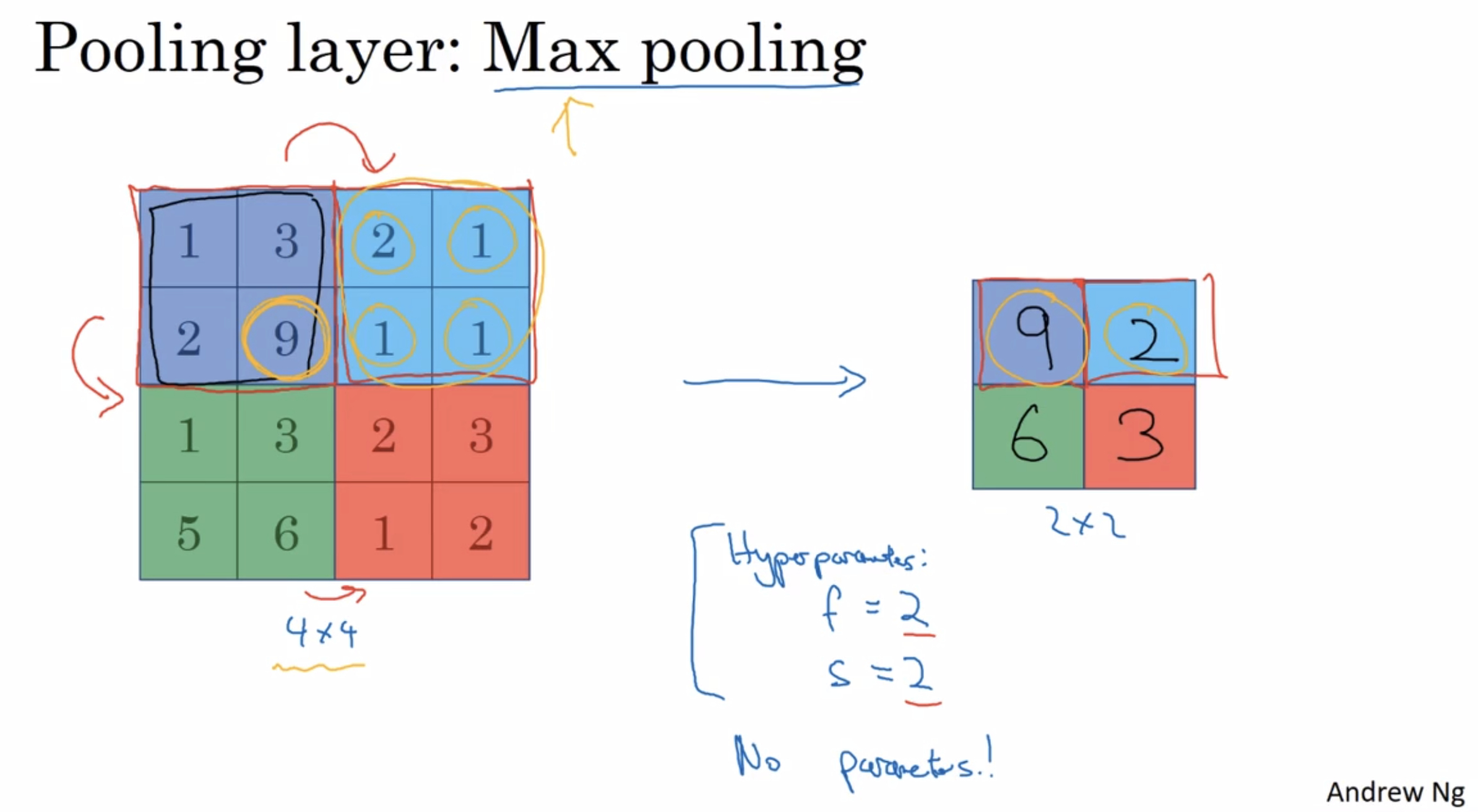
Max Pooling : take the max over the region
the reason people use max pooling:
- the intuition behind max pooling
if you think of this 4 by 4 region as some set of features, the activations in some layer of the neural network, then a large number means that it’s maybe detected a particular feature. if these features detected anywhere in this filter, then keep a high number. but if this feature is not detected, then the max of all those numbers is still itself quite small. - it’s been found in a lot of experiments to work well
maybe this is the main reason
Max pooling has a set of hyperparameters but it has no parameters to learn. Just a fixed computation.
an example with some different hyperparameters
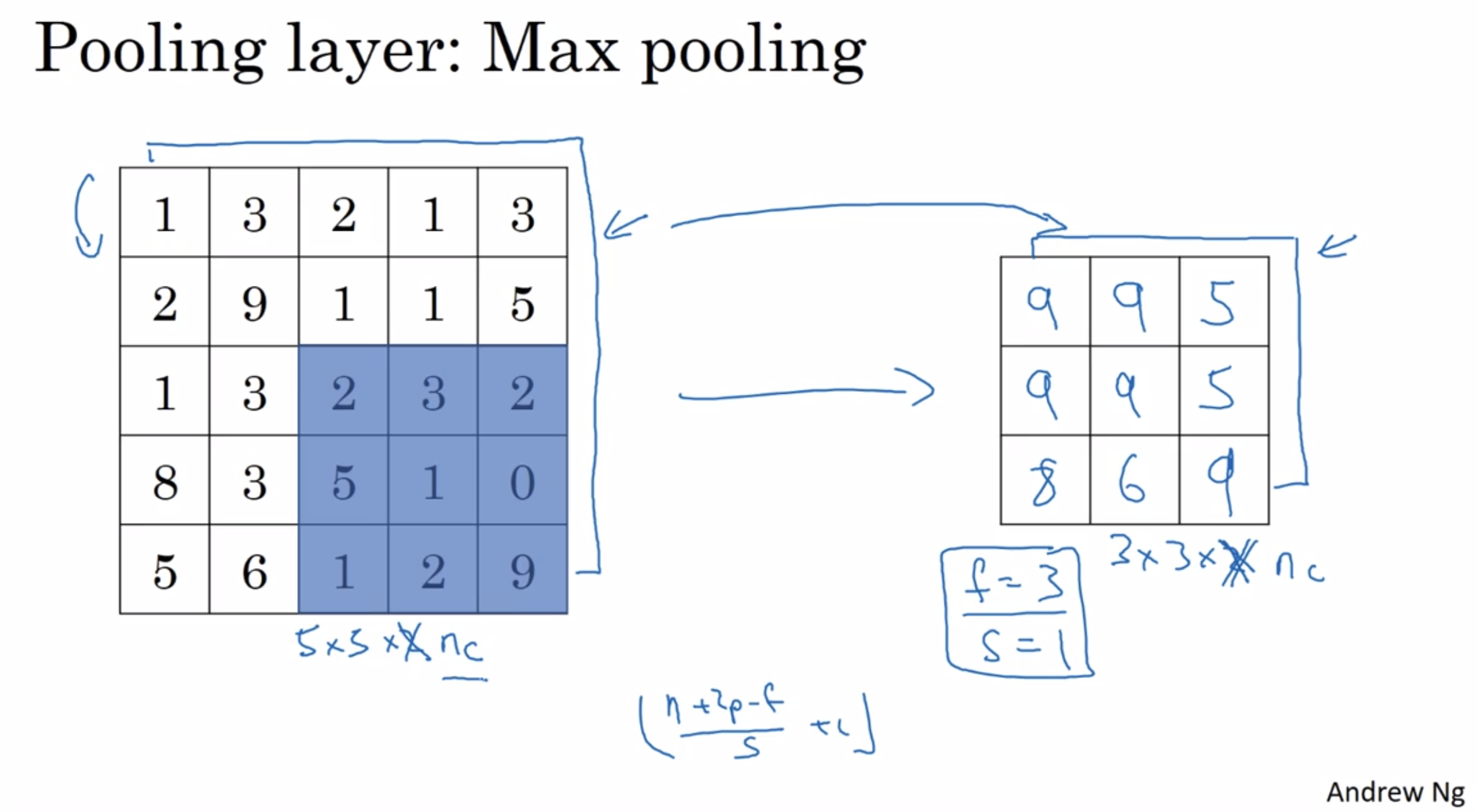
The max pooling computation is done independently on each of these Nc channels.
(different from the convolution operation)
¶Average pooling
mention briefly : average pooling
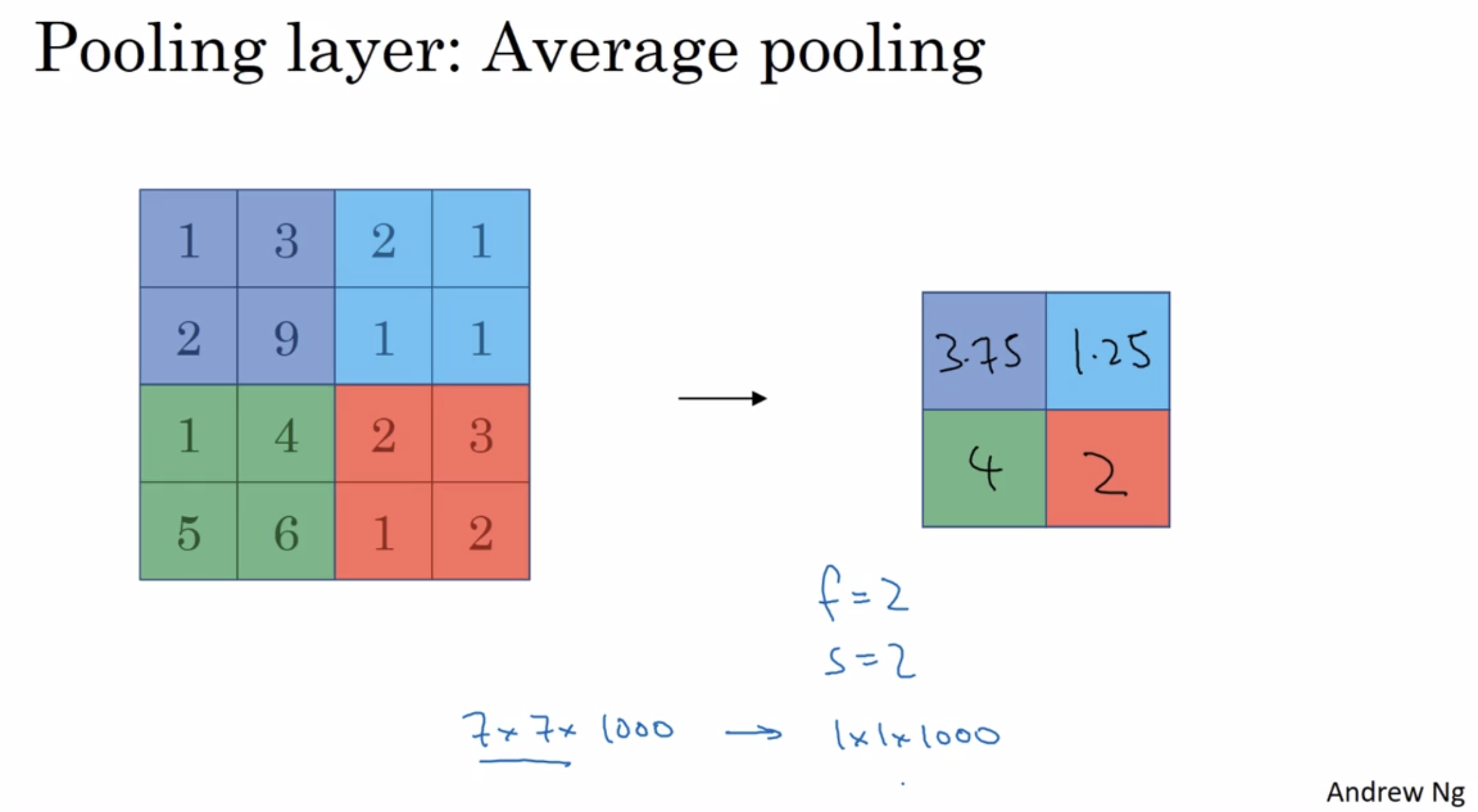
As a matter of fact, max pooling used much more in the neural network than average pooling.

common chosen hyperparameters:
- f = 2, s = 2
this has the effect of shrinking the height and width of the representation by a factor of two - f = 3, s = 2
when you do max pooling, usually, you do not use any padding. (One exception)
¶Convolutional neural network example
You now know pretty much all the building blocks of building a full convolutional neural network.
Let’s look an example.
Let’s say you’re inputting an image which is 32 by 32 by 3, so it’s an RGB image and maybe you’re trying to do handwritten digit recognition. Let’s throw the neural network to do this.
What I’m going to use in this slide is inspired, it’s actually quite similar to one of the classic neural networks called LeNet-5, which is created by Yann LeCun many years ago.
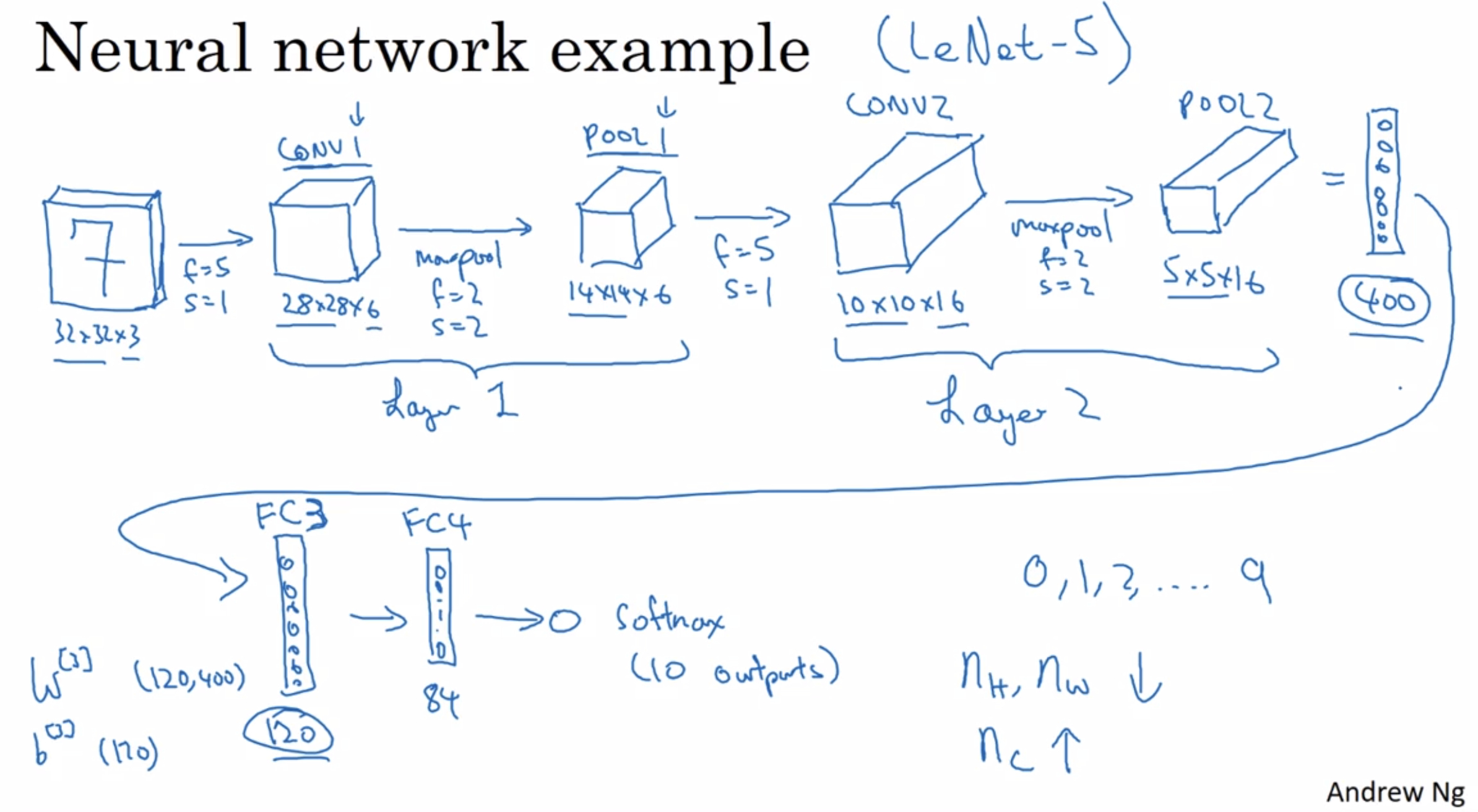
When people report the number of layers in a neural network usually people just record the number of layers that have weight, that have parameters. The pooling layer only have a few hyperparameters, so I’m going to treat that as Layer 1.
The fully connected layer is just like the single neural network layer.
how to choose these types of hyperparameters?
One common guideline is to actually not try to invent your own settings of hyperparameters, but to look in the literature to see what hyperparameters you work for others. And to just choose an architecture that has worked well for someone else, and there’s a chance that will work for your application as well.
some more details
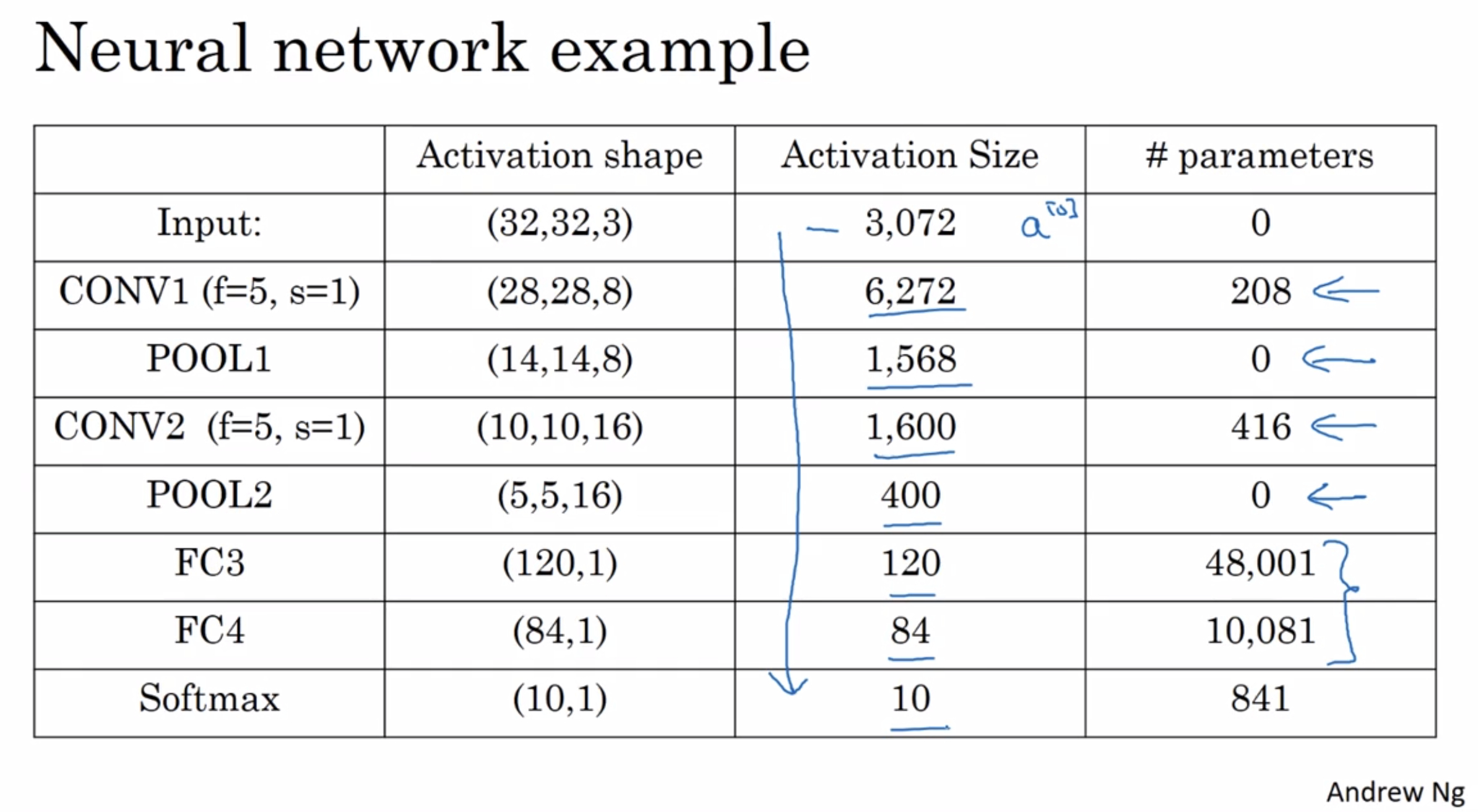
Notice:
- The max pooling layers don’t have any parameters.
- The conv layers tend to have relatively few parameters.
- The activation size tends to maybe go down gradually as you go deeper in the neural network. if it drops too quickly, that’s usually not great for performance as well.
- CONV1 have 8 filters, so #parameters = (5 * 5 + 1) * 8 = 208
CONV2 have 16 filters, so #parameters = (5 * 5 + 1) * 16 = 416
FC3 #parameters = 400 * 120 + 1 = 48001
FC4 #parameters = 120 * 84 + 1 = 10081
a lot of onvolutional neural networks have properies or have patterns similar to these.
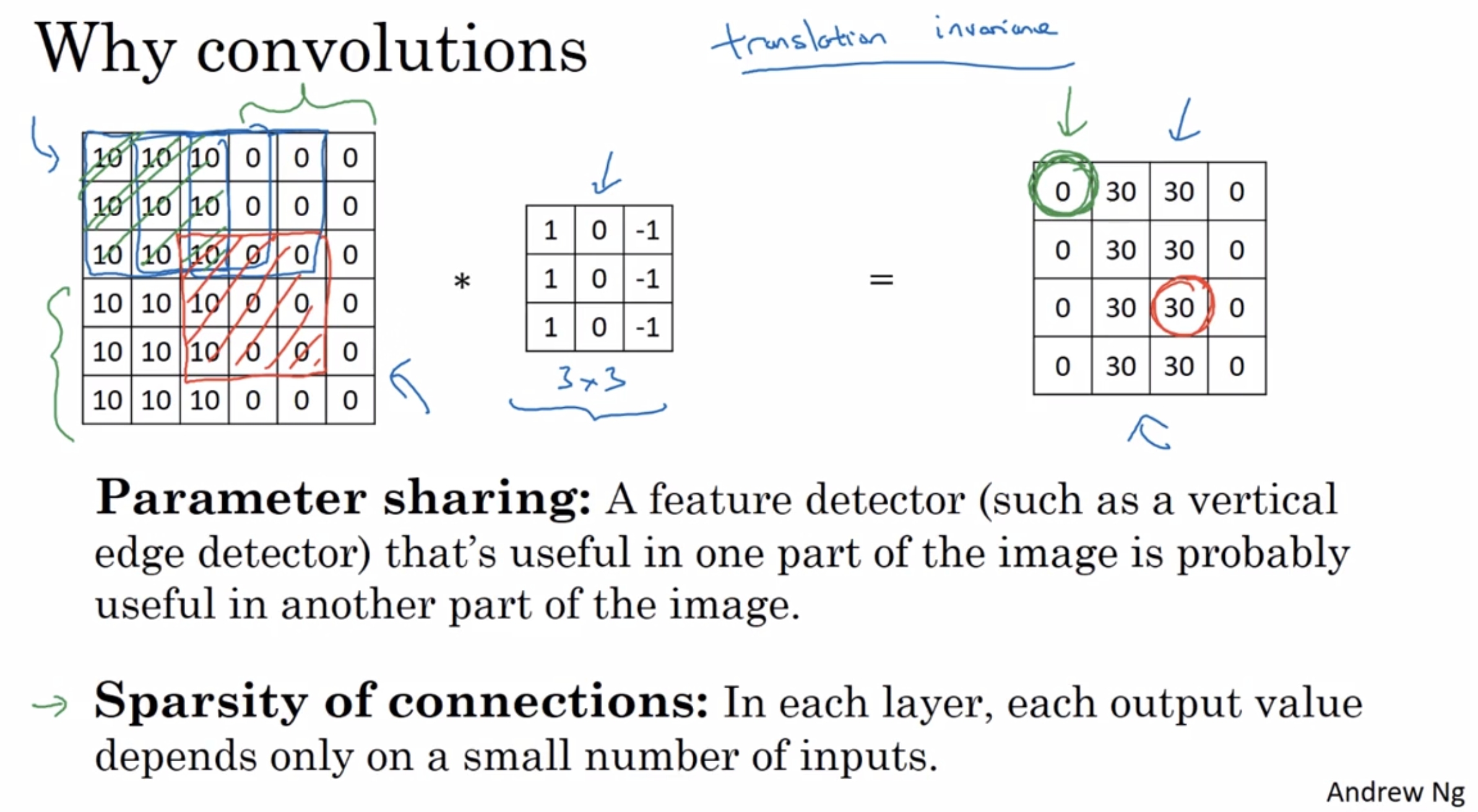
¶Why convolutions?
- why convolutions are so useful when you include them in your neural networks
- how to put convolutions and neural networks together or say how to train a convolutional neural network when you have a label training set
There are two main advantages of convolutional layers over just using fully connected layers and the advantages are parameter sharing and sparsity of connections.

convolutional layers : small parameters : parameter sharing and sparsity of connections
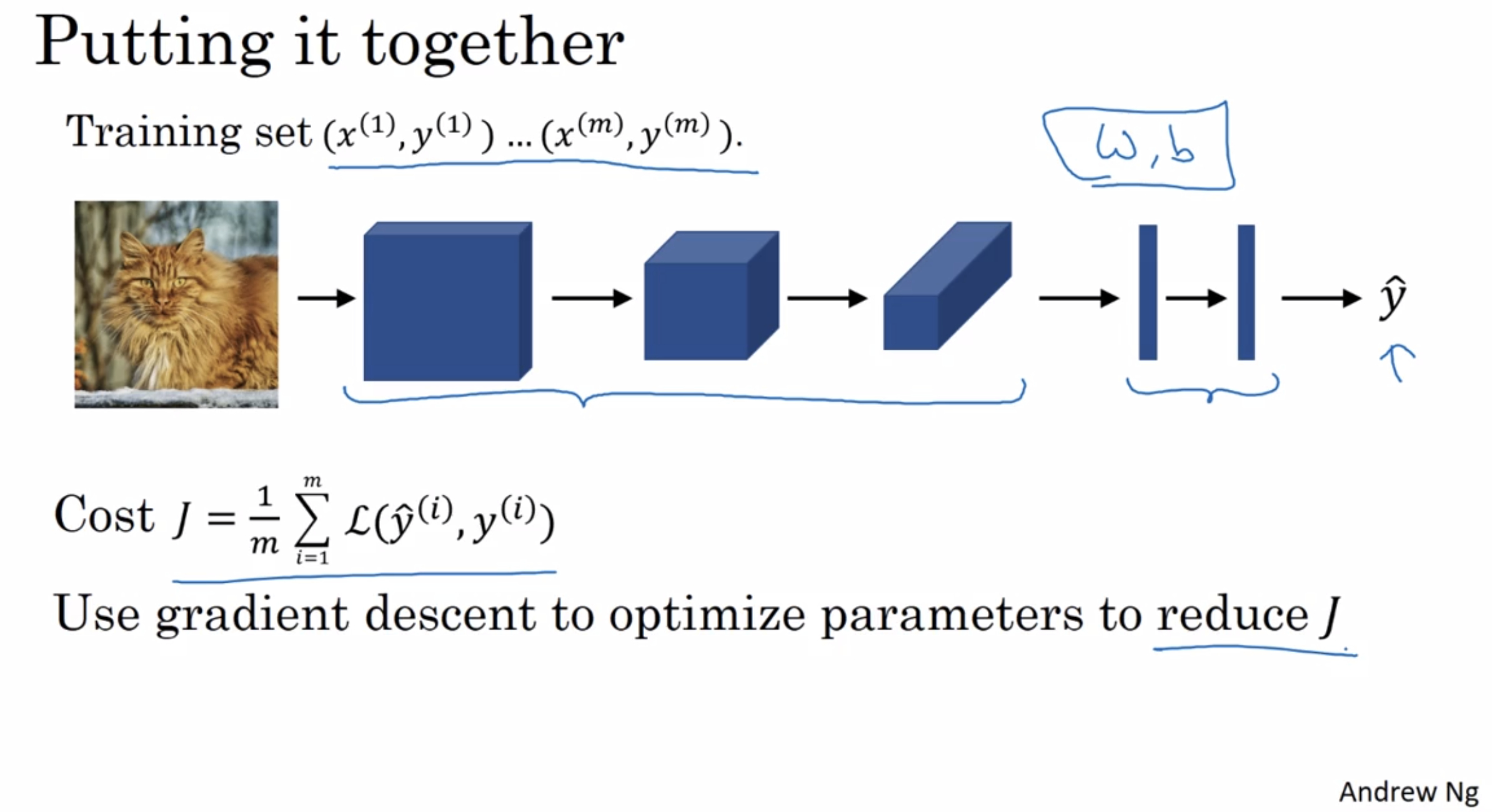
how to train:
use gradient descent or other algorithm to optimize parameters to reduce the cost function
¶Yann LeCun interview
Part of the interview
Andrew Ng : What advice do you have for someone wanting to get involved in the AI, break into AI?
Yann LeCun : Hhh, I mean, it’s such a different world now, than when it was when I got started. But I think what’s great now is it’s very easy for people to get involved at some level, the tools that are available are so easy to use now, in terms of whatever. You can have a run through on the cheap computer in your bedroom, and basically train your conventional net or your current net to do whatever, and there’s a lot of tools. You can learn a lot from online material about this without… it’s not very onerous. So you see high school students now playing with this right? Which is kind of great, I think and they certainly are growing interest from the student population to learn about machine learning and AI and it’s very exciting for young people and I find that wonderful I think. So my advice is, if you want to get into this, make yourself useful. So make a contribution to an open source project, for example. Or make an implementation of some standard algorithm that you can’t find the code of online, but you’d like to make it available to other people. So take a paper that you think is important, and then reimplementation the algorithm, and, then put it open source package, or contribute to one of those open source packages. And if the stuff you write is interesting and useful, you’ll get noticed. Maybe you’ll get a nice job at a company you really wanted a job at, or maybe you’ll get accepted in your favorite PhD program or things like this. So I think that’s a good way to get started.


