b站视频链接:北京理工大学ACM冬季培训课程 课程刷题地址 2020BIT冬训-并查集&最小生成树 但是没得密码。。。
并查集&最小生成树
并查集
问题提出
假设有 n 个强盗,其中可能有很多帮派,给出关系链(某人和某人是同伙)。然后给出多个查询,询问其中两个人是不是一个帮派
问题解决方法
图染色
将连接两个端点及其所在块涂成一个颜色。合并时复杂度较高,查询时为 $O(1)$ 。
并查集
将某个强盗作为这个团队的代表人物(头目)。在修改时,使原本两个团队的代表人物(头目)具有从属关系(a,b 两个集合合并后,若 b 原来的头目是 a 的头目的下属,那么实际上 b 合并后的最高头目还是 a 的头目,通过修改头目的从属关系合并集合)。对于查询,只需查询是否两个集合的代表元素是同一个。在修改较多时,均摊复杂度优于图染色。
并查集
概念
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。
建立集合
查找某个元素是否在一给定集合内(或查找一个元素所在的集合)
合并两个集合
“并”“查”“集”三字由此而来。
并查集能解决的问题一般可以转化成这样的形式:初始时 n 个元素分属不同的 n 个集合,通过不断的给出元素间的联系,要求 实时 的 统计元素间的关系 (即是否存在直接或间接的联系)。
并查集本身不具有结构,可以用数组、链表以及树等实现。最常用的是 数组 实现
实现
数组实现:
1. 建立集合,初始化
1 2 3 4 5 void init () for (int i = 1 ; i <= n; i++) father[i] = i; }
2. 合并集合&查找集合所属元素
查找就是寻找头目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int find (int x) while (father[x]!=x) x=father[x]; return x; } int find (int x) if (father[x]!=x) return find (father[x]); else return x; }
因此,比较两个元素 x,y 是否是同一集合的方法就是比较 find(x) 是否等于 find(y)。
1 2 3 4 5 6 7 8 9 bool judge (int x, int y) x = find (x); y = find (y); if (x == y) return true ; else return false ; }
合并集合的方法就是将其中一个点所在集合的根结点的父结点设定为另一个点所在集合的根结点。
1 2 3 4 5 6 void union1 (int x, int y) x = find (x); y = find (y); father[y] = x; }
优化
路径压缩
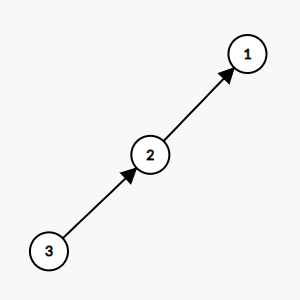
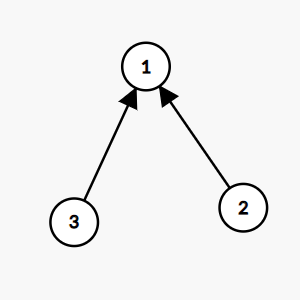
路径压缩就是在找完根结点之后,在递归回来的时候顺便把路径上元素的父亲结点都设为根结点
路径压缩前示意图
路径压缩后示意图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int find (int x) if (father[x]!=x) father[x]=find (father[x]); return father[x]; } int find (int x) int r=x,q; while (r!=father[r]) r=father[r]; while (x!=r) { q=father[x]; father[x]=r; x=q; } return r; }
(这个优化平时都可以用,但是对于某些题会造成麻烦,例如加权并查集,这样的题需要特殊处理)
按秩合并(启发式合并)
在合并两个集合(就是两棵树)的时候,如果待合并的树的深度不相同,那么就有两种选择:
一种是以深度较小的树的根结点为新的根结点
另一种是以深度较大的树的根结点为新的根结点
而事实上,选择以深度较大的树的根节点为新的根节点较好,因为这样的话新生成的树深度会更小,可以防止树的退化 (退化指越来越接近链表,即深度大而分支少),使资源利用更合理。而合并时这样选择,就叫作“按秩合并 ”
按秩合并的基本思想是将深度较小的树指到深度较大的树的根上
按秩合并需要新开一个数组depth来记录深度,depth[x]是("以 x 为根结点的树"的某个叶结点到 x 的最长路径上)边的数目的一个最大值。(即以 x 为根结点的树的树高)
(这个优化比较麻烦,简单题一般不用)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void init () int i for (i = 1 ; i <= n; i++) { father[i] = i; depth[i] = 0 ; } } void union1 (int x, int y) int fx = find (x), fy = find (y); if (depth[fx] > depth[fy]) father[fy] = fx; else { father[fx] = fy; if (depth[fx] == depth[fy]) depth[fy]++; } }
应用
变种
加权并查集
最小生成树
Prim 算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void MiniSpanTree_PRIM (MGraph G, VertexType u) k = LocateVex (G, u); for (j = 0 ; j < G.vexnum; ++j) if (j! = k) closedge[j] = { u, G.arcs[k][j].adj }; closedge[k].lowcost = 0 ; for (i = 1 ; i < G.vexnum; ++i) { k = mininum (closedge); printf (closedge[k].adjvex, G.vexs[k]); closedge[k].lowcost = 0 ; for (j = 0 ; j < G.vexnum; ++j) if (G.arcs[k][j].adj < closedge[j].lowcost) closedge[j] = { G.vexs[k], G.arc[k][j].adj }; } }
Prim 算法的 C++ 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 void prim (int u) int sum_mst = 0 ; for (int i = 1 ; i <= n; i++){ lowcost[i] = Map[u][i]; mst[i] = u; } mst[u] = -1 ; for (int i = 1 ; i < n; i++){ int minn = INF; int v = -1 ; for (int j = 1 ; j <= n; j++){ if (mst[j] != -1 && lowcost[j] < minn) { v = j; minn = lowcost[j]; } } if (v != -1 ) { mst[v] = -1 ; sum_mst += lowcost[v] for (int j = 1 ; j <= n; j++) { if (mst[j] != -1 && lowcost[j] > Map[v][j]) { lowcost[j] = Map[v][j]; mst[j] = v; } } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 int edges[MAXN][MAXN];int dist[MAXN];bool vis[MAXN];void add_edge (int from, int to, int value) edges[from][to] = max (edges[from][to], value); edges[to][from] = max (edges[to][from], value); } void init () memset (edges, -1 , sizeof (edges)); memset (dist, -1 , sizeof (dist)); memset (vis, false , sizeof (vis)); } int prim (int n) vis[1 ] = true ; for (int i = 2 ; i <= n; i++) dist[i] = edges[1 ][i]; int ret = 0 ; for (int i = 2 ; i <= n; i++) { int x = 1 ; for (int j = 1 ; j <= n; j++) if (!vis[j] && dist[j] > dist[x]) x = j; ret += dist[x]; vis[x] = true ; for (int j = 1 ; j <= n; j++) if (!vis[j]) dist[j] = min (dist[j], edges[x][j]); } return ret; }
Kruskal 算法
Kruskal 算法的 C++ 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct Edge { int from, to, value; bool operator < (const Edge& rhs) const { return value < rhs.value; } }; int Kruskal (Edge* edges, int m) sort (edges, edges + n); int ret = 0 ; for (int i = 0 ; i < m; i++) { if (find (edges[i].from) == find (edges[i].to)) continue ; ret += edges[i].value; merge (edges[i].from, edges[i].to); } return ret; }